

What do Uruguay’s running presidential candidates’ tweet? Part I
“I like politics, I believe it is an appropriate environment to try to change certain issues and build a better country. I also like Twitter, I believe it is an appropriate environment to share what we are interested in with the rest of the world.”
Elections will soon take place and candidates resort to this social network to make themselves be known and gain exposure. To this end, they create specific and specialized content aimed at their readers (and potential voters) to stand out and contrast with the rest.
I found it interesting to investigate what the candidates say, think, and share in their networks.
I tried to gather data with Twitter API Standard, but it has limited access to “large” contents of information, so I decided to scrape the page using DataMiner. This is how I extracted all the tweets issued by the following candidates from January 1, 2018 to August of the current year: Pablo Mieres, José Amorín Batlle, Fernando Amado, Verónica Alonso, Edgardo Novick, Luis Lacalle Pou, Carolina Cosse, Daniel Martínez, Jorge Larrañaga, and Ernesto Talvi. Some candidates are not highly active, so I had to go a little further back in time, given that some analyses require a great deal of information.
Then with Python I parsed the results and did some primary calculations. I inserted the information into a database and used Cognos to connect to the database and prepare the reports. For Network Analysis (SNA) I used i2 Analyst’s Notebook.
Beginning of the Analysis
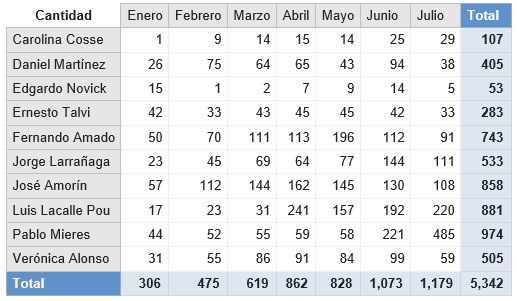
One way to analyse which potential presidential candidate is most active on the net is to look at the number of tweets they make per month.

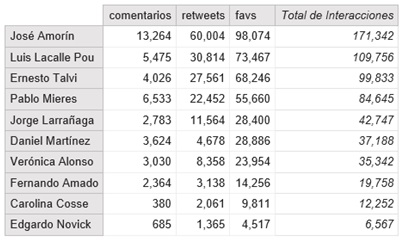
By analysing the number of followers, we can find out which candidate is the most influential. However, you can have a large number of followers who do not interact much with the messages sent. It is more accurate to consider interaction measures. In the following graph you can see the absolute number of likes, comments, and retweets that each candidate has received, considering the messages they have sent, apart from retweets:
The foregoing graph is likely to be unfair if the measurement is made in absolute terms. Probably, he who has tweeted the most, might have received a higher number of RT/FAV/COMMENTS. It would be more accurate to observe the average number of likes received per tweets and the retweets that each one has received, considering only their own tweets (apart from retweets):
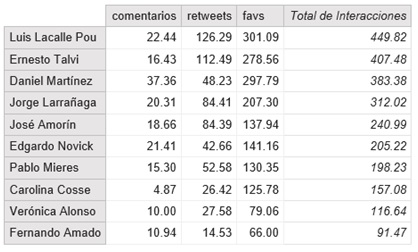
I find it impressive that Fernando Amado (who on average has the fewest interactions per tweet) has 91 interactions on average. If I get 10 favs in a tweet, and I am astounded!
Turn me on, candidate, turn me on!
According to some heuristic theory, if a tweet has more comments than favs or retweets, it is because something in it has made twitters angry. We can call this a “provocative” tweet.
Now let us see how many of these tweets each candidate made:
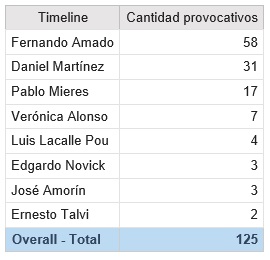
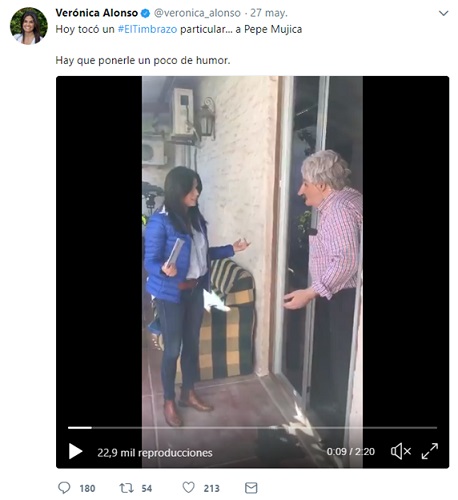
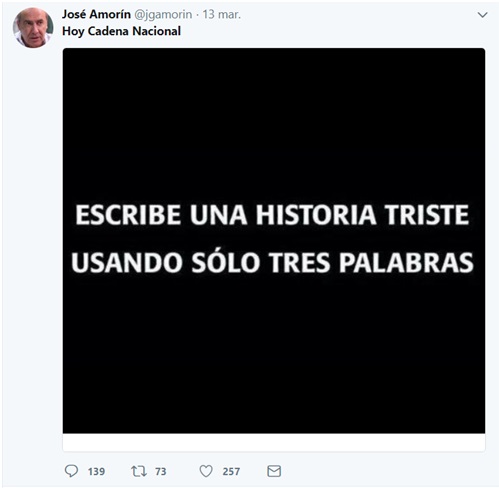
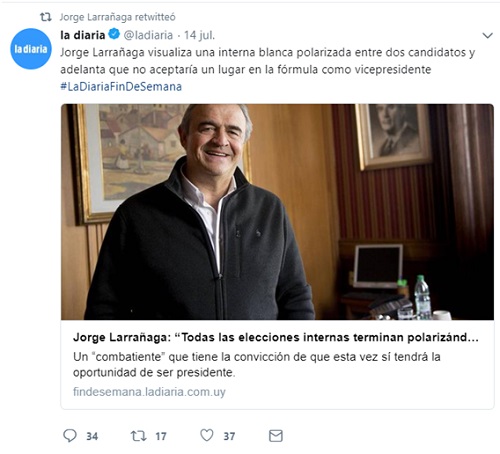
The most “provocative” tweet of each candidate was:







Who is the most talkative?
To learn who the most talkative is, we will consider the number of words they used, and the average number of words for each tweet. The analysis did not include hashtags, links to pages and stopwords (I will explain this later).
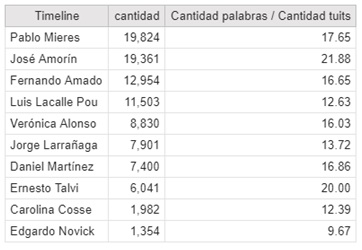
The one who has spoken the most is Mieres, but that is because he tweets a lot. If we see the average of words per tweet the analysis is different:
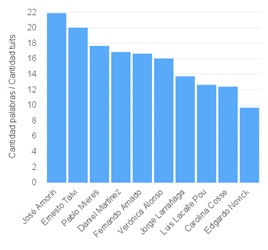
Much’ado about nothing
One thing is to talk a lot, but it is not meaningful if you always repeat the same words. That is why I found it interesting to analyse who is the candidate with the richest vocabulary (at least on the net).
There are people who speak little but say a lot.
Therefore, I calculated the number of different words / total words used by each candidate.
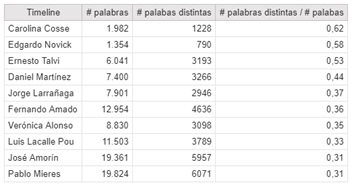
If we compare this table with the previous one, we can appreciate that it is the same but inverted. It is obvious that those who speak the most, are repetitive.
What do they talk about?
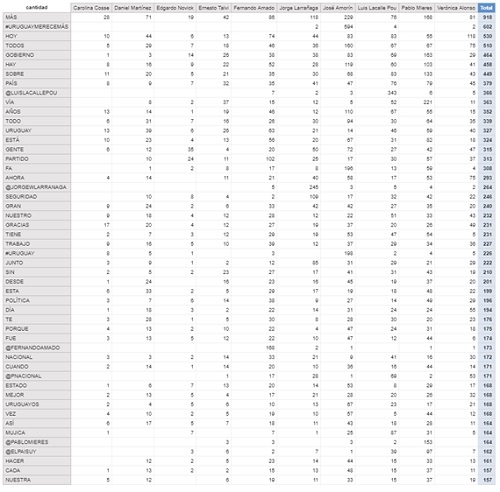
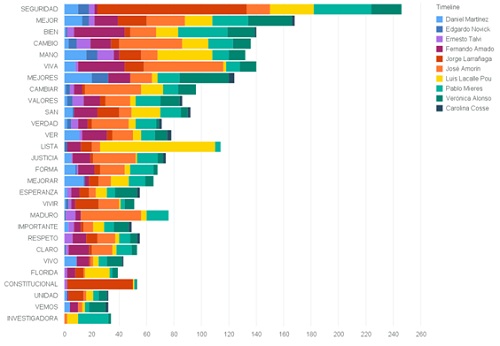
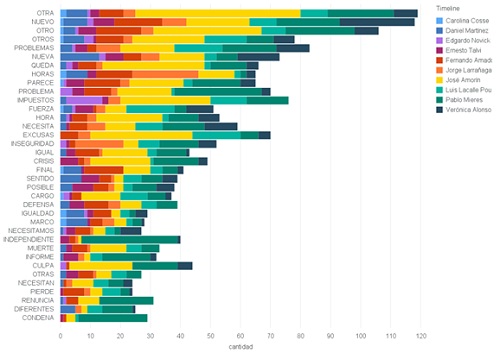
The following graph shows the most repeated words, considering all the tweets.
I removed from the list the words that do not add value (known in the jargon as stop-words), some examples of these words are: [‘OF’, ‘THAT’, ‘IN’, ´HE’, ‘TO’, ‘SHE’, ‘AND’, ‘IT’, ‘FOR’, ‘ONE’, ‘CON’, ‘HIS/HER/ITS’, ‘A’, ‘NO’, ‘THE’, ‘ LIKE/AS’, ‘IS’, ‘BECAUSE’, ‘IF’, ‘THAT’, ‘BE’, ‘NOW’, ‘BUT’, ‘OR’, ‘THIS’]
The graph shows the 50 most frequently-used words with their frequency, classified per candidate:
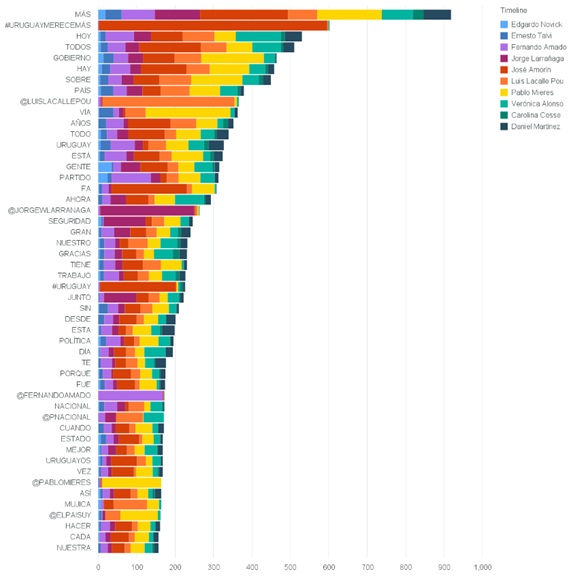
For or against? For?
An elementary feeling analysis (or opinion mining) is to weigh each word according to its connotation: positive or negative. It is a way of identifying candidates’ attitude.
There are dictionaries that have already classified some words. I resorted to a Spanish dictionary that has classified 2.496 words. I enlarged it to 497,560 words with a lemmatizer! By matching the established form of the words used by candidates with the established form of the words classified by connotation as search criteria, I increased the amount of coincidences.
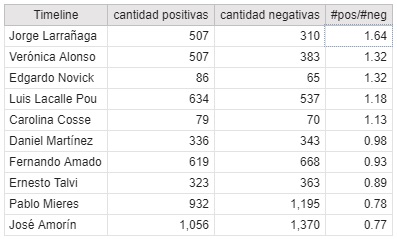
The table below shows the most repeated positive and negative words.
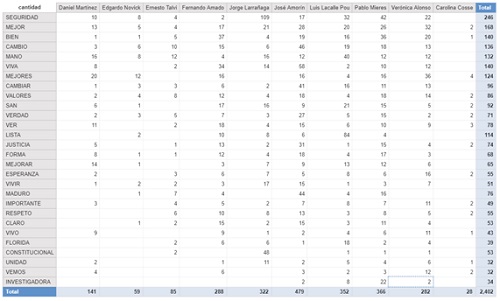
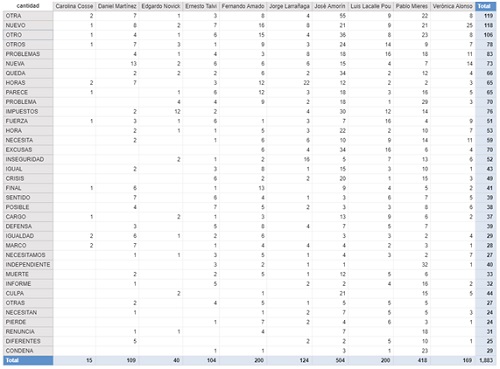
I believe that words such as ‘another,’ ‘new,’ hours’ among others, which are classified as negatives by the dictionary, do not seem to have a negative connotation as such. There are some words that have a positive connotation in isolation, but I think in context, they must have been used with a negative connotation, for instance: security.
In spite of what was said in the previous paragraph, I believe that seeing the number of words that in isolation are inherently positive, plus the number of negative words per candidate, and calculating the relationship for each of candidates, we can have an idea of which politician uses a rather positive language, and which one a more negative one. I also found it was interesting to find the three positive and three negative words that each candidate likes to repeat the most. Obviously, many words that are not catalogued in the dictionary I used, are lost, but it is an approximation:
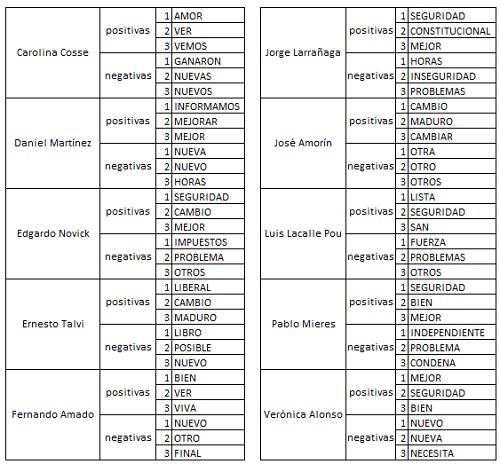
I do not want to be ordinary
It would also be relevant to find out what each candidate plans to do, what issue/s their major focus is on. The easiest way to do this is by term frequency (tf), where all we must do is to count how many times a word is repeated by every candidate. The problem is that there are unimportant words with a high frequency rate, such as stop-words. There are some topics everybody talks about (I imagine politics, security, education, among others) that will not be considered.
For this I employed inverse document frequency (idf) for each word (documents’ inverse frequency) that lowers the importance to words shared by all candidates and focuses on the words which are rarely share. The formula I used was the following:
For frequency I used normalized frequency (to avoid favouring those who tweet more) which I found by dividing the number of times a word is repeated, by the maximum frequency of a word in the document.
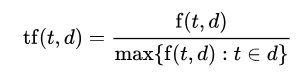
To calculate inverse document frequency, I divided the total number of candidates (10) by the number of candidates using the word being analysed and taking the logarithm of that division.
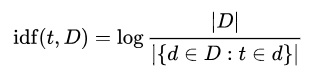
To round up word frequency, considering document inverse frequency, the other two are multiplied.
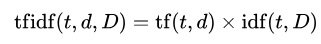

Birds of a feather…
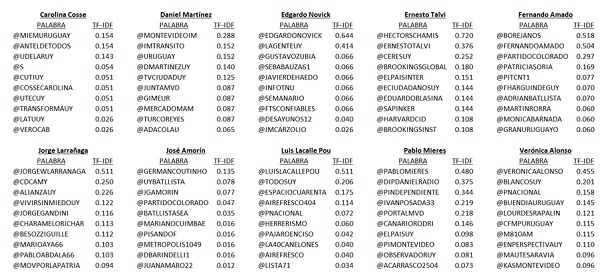
Usually, when somebody else’s material is retweeted, the author is mentioned or quoted. I applied the same technique that I explained in the previous point, to see which other matters candidates refer to more, considering tf-idf to see in which they differ mostly, and disregard quotes seldom shared:
Next time, instead of analysing candidates’tweets, we will analyze the networks built according to the people that an individual follows.
Data Analytics & Information Management consultant.