

¿De qué hablan en Twitter los (posibles) candidatos a presidente de Uruguay? Primera parte
Me gusta la política, la entiendo como un buen ámbito para tratar de cambiar las cosas y construir un país mejor. También me gusta Twitter, lo entiendo como un buen ámbito para compartir con el mundo cosas que me interesan.
Se vienen las elecciones y los candidatos a presidente utilizan esta red social para darse a conocer y obtener visibilidad. Por eso crean contenido específico y especializado para sus lectores (y posibles votantes) intentando de alguna forma diferenciarse y destacarse del resto.
Me resultó interesante investigar qué es lo que dicen los candidatos en sus redes, qué opinan y comparten.
Intenté obtener los datos con la API Standard de Twitter pero se me complicó porque tiene límites en el acceso a “grandes” volúmenes de información así que decidí scrapear la página utilizando DataMiner. De esta forma extraje todos los tweets desde el 1° de enero de 2018 hasta agosto del mismo año para los siguientes candidatos: Pablo Mieres, José Amorín Batlle, Fernando Amado, Verónica Alonso, Edgardo Novick, Luis Lacalle Pou, Carolina Cosse, Daniel Martínez, Jorge Larrañaga y Ernesto Talvi. En el caso de los candidatos que no son muy activos tuve que retrotraerme un poco más en el tiempo ya que algunos análisis requieren grandes volúmenes de información.
Luego con Python parseé los resultados e hice algunos cálculos primarios. Inserté la información en una Base de Datos y utilicé Cognos para conectarme a la base y armar los reportes. Para el análisis de redes (SNA – Social Network Analysis) utilicé i2 Analyst’s Notebook.
Comienza el análisis
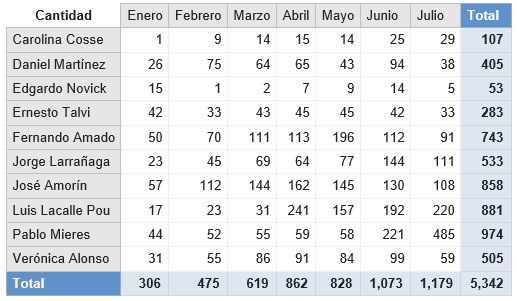
Una forma de analizar cuál es el posible candidato presidencial más activo en la red es observar la cantidad de tweets que realiza por mes.

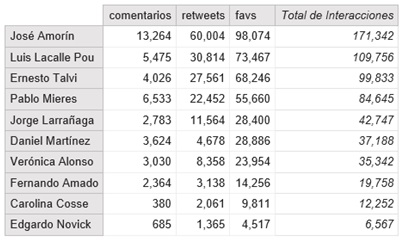
Para intentar descubrir qué tan influyente es cada candidato lo primero que surge es analizar la cantidad de seguidores. Sin embargo, se puede tener una gran cantidad de seguidores y que no interactúen mucho con las publicaciones que uno hace. Es más exacto (a mi parecer) tener en cuenta medidas de interacción. En el siguiente gráfico se puede ver la cantidad absoluta de me gusta, comentarios y retweets que recibió cada uno, teniendo en cuenta tweets propios (y no los retweets):
El gráfico anterior puede ser medio injusto ya que si medimos en términos absolutos es muy probable que el que haya tweeteado más haya cosechado mayor cantidad de RT/FAV/COMENTARIOS. Algo más justo podría ser ver la cantidad promedio por tweet de me gusta, comentarios y retweets que recibió cada uno teniendo en cuenta nuevamente únicamente los tweets propios (y no los retweets):
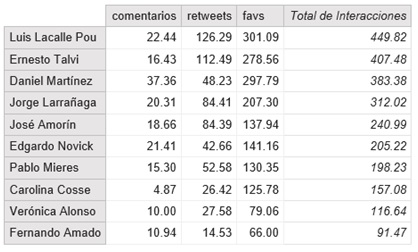
Me resulta impresionante que Fernando Amado (que es el que en promedio tiene menos interacciones por tweet) tenga 91 interacciones promedio. ¡A mí me dan 10 favs en un tweet y me emociono!
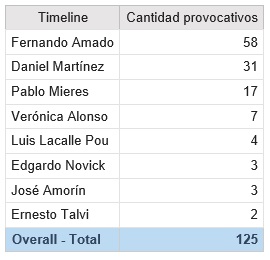
¡Provócame, candidato, provócame!
Hay una heurística que indica que si un tweet tiene más comentarios que favs o retuits es porque por algún motivo hizo enojar a los twitteros. Podemos llamarlo un tweet “provocativo”.
Ahora veamos la cantidad de estos tweets que cada candidato realizó:
El tweet más “provocativo” de cada candidato fue:

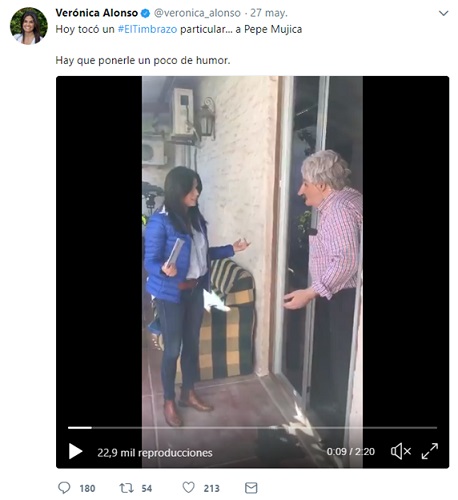

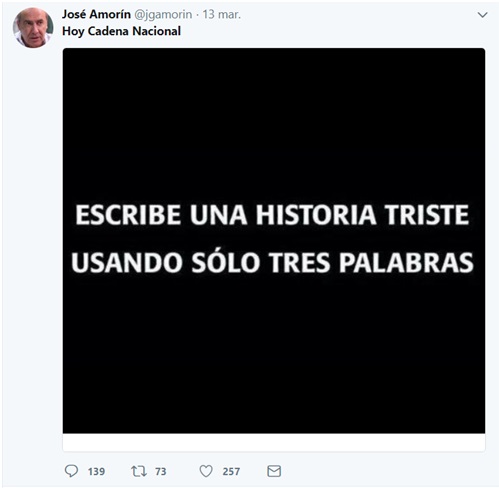





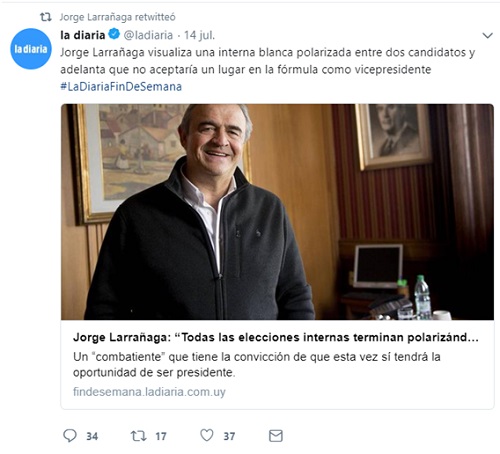
¿Quién es el más charlatán?
Para ver quién es el que más habla vamos a tener en cuenta la cantidad de palabras que utilizaron y también la cantidad de palabras promedio de cada tweet. Para realizar el análisis no se tuvieron en cuenta los hashtags ni links a páginas ni tampoco stopwords (lo explicaré más adelante).
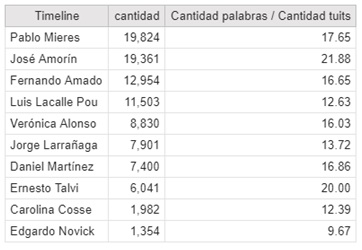
El que más ha hablado es Mieres, pero eso es porque a su vez tweetea mucho. Si vemos el promedio de palabras por tuit la cosa cambia:
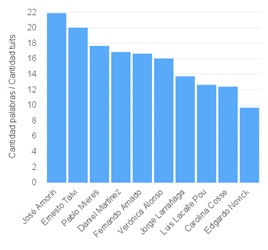
Mucho ruido y pocas nueces
Una cosa es hablar mucho pero no está bueno si siempre se repiten las mismas palabras. Por esto me resultó interesante analizar quién es el candidato con el vocabulario más rico (al menos en la red).
Hay gente que habla poco pero dice mucho.
Para analizar esto entonces calculé para cada candidato la cantidad de palabras distintas / total de palabras utilizadas.
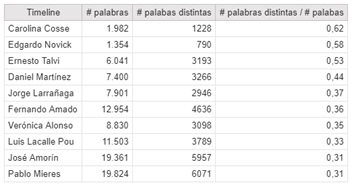
Si comparamos esta tabla con la anterior vemos que es prácticamente la misma pero invertida. Resulta bastante obvio que los que más hablan más se repiten.
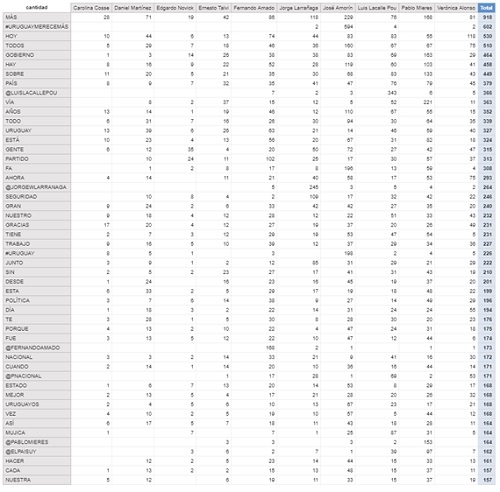
¿Sobre qué hablan?
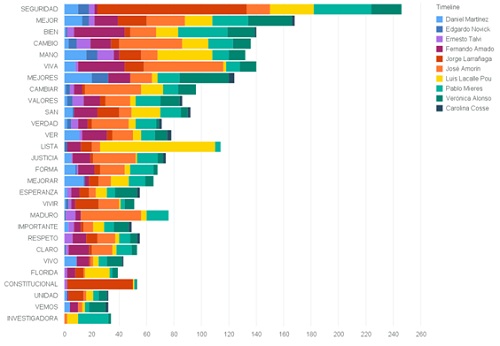
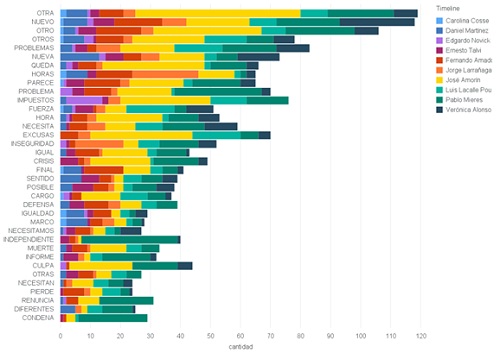
En el siguiente gráfico se ven las palabras que más se repiten, teniendo en cuenta todos los tweets.
Quité de la lista las palabras que no agregan valor (conocidas en la jerga como stop-words), algunos ejemplos de estas palabras son: [‘DE’, ‘QUE’, ‘EN’, ‘LA’, ‘A’, ‘EL’, ‘Y’, ‘SE’, ‘PARA’, ‘UNA’, ‘CON’, ‘SU’, ‘UN’, ‘NO’, ‘LOS’, ‘COMO’, ‘LAS’, ‘ES’, ‘LO’, ‘POR’, ‘DEL’, ‘SI’, ‘ESE’, ‘EL’, ‘EN’, ‘SER’, ‘LA’, ‘YA’, ‘PERO’, ‘ESO’, ‘LE’, ‘AL’, ‘O’, ‘ESTE’]
En el gráfico se observan las 50 palabras más comunes con su frecuencia, dividido para cada candidato:
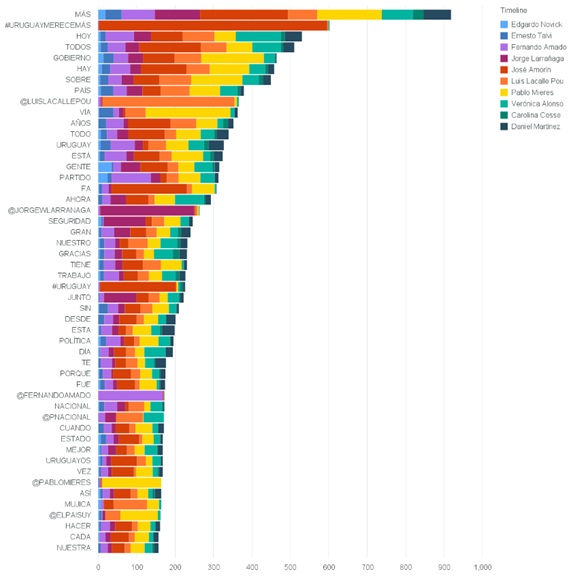
¿Por la positiva?
Una forma bastante básica de hacer análisis de sentimiento (o minería de opinión) es ponderando cada palabra de acuerdo a su connotación: positiva o negativa. Es una manera de identificar la actitud de cada candidato.
Hay diccionarios que ya tienen catalogadas algunas palabras. Yo utilicé uno en español que tiene clasificadas 2.496 palabras. Para ampliarlo sumé un lemmatizador ¡con 497.560 palabras!, ya que hallando la forma canónica de las palabras que utilizaron los candidatos y la forma canónica de las palabras que tengo clasificadas por sentimiento para utilizar como criterio de búsqueda incremento la cantidad de coincidencias.
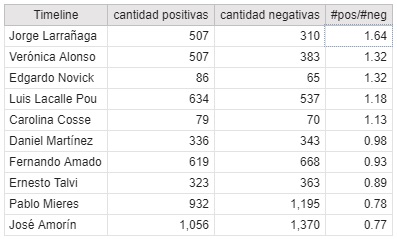
Vemos a continuación las palabras positivas que más se repiten y también las negativas.
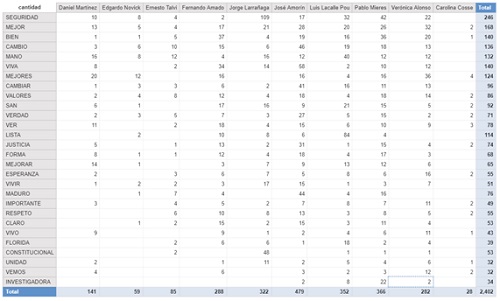
Palabras negativas
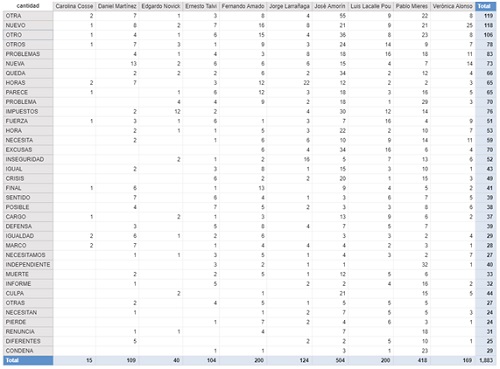
A priori hay palabras con las que no estoy de acuerdo con la categorización en el diccionario, sobre todo con algunas negativas, por ejemplo palabras como ‘otra, ‘nuevo’, ‘horas’, etc. no me parece que tengan inherentemente una connotación negativa. A su vez también hay palabras que tienen una connotación positiva de forma aislada pero estoy casi seguro que en el contexto en la que la utilizaron los candidatos no fue de manera positiva, por ejemplo: seguridad.
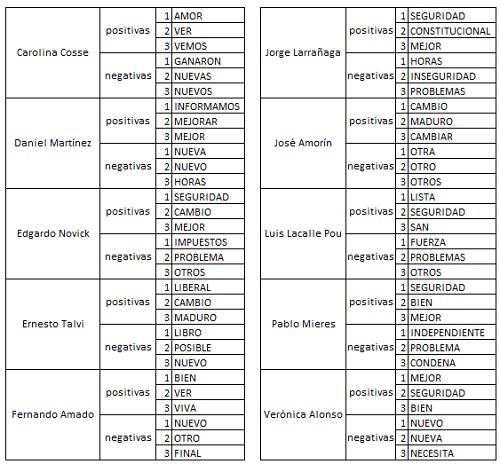
A pesar de lo dicho en el párrafo anterior creo que viendo la cantidad de palabras que de manera aislada son inherentemente positivas y la cantidad de palabras negativas por candidato y calculando la relación para cada uno de ellos nos puede dar una idea de cuál político utiliza un lenguaje más bien positivo y cuál más negativo. También me resultó interesante ver por cada candidato las tres palabras positivas y tres palabras negativas que más le gusta repetir. Evidentemente se pierden muchas palabras que no están catalogadas en el diccionario que utilicé, pero es una aproximación:
No quiero ser normal
Un análisis interesante podría ser ver qué propone cada uno, sobre qué es lo que más habla. Para esto lo más sencillo sería ver el term frequency (tf) (frecuencia del término) donde lo único que habría que hacer es ver cuántas veces repite cada palabra cada uno de los candidatos. El problema es que hay palabras que se pueden repetir mucho pero no ser importantes como por ejemplo las stop-words de las que ya hablé. Tampoco me interesa en realidad tener en cuenta cuestiones sobre las que todos hablan (imagino que todos deben hablar sobre política, seguridad, educación, etc.), si todos hablan de eso sin dudas no es un diferencial.
Para esto tuve en cuenta el inverse document frequency (idf) de cada palabra (el inverso de la frecuencia del documento) que le baja la importancia a las palabras que son comúnmente usadas por todos los candidatos y aumenta las palabras que no comparten tanto.
Formalmente la fórmula que usé fue la siguiente:
Para la frecuencia utilicé una frecuencia normalizada (para evitar favorecer a los que tuitean más) que la hallé dividiendo la cantidad de veces que se repite la palabra entre la frecuencia máxima de algún término en el documento
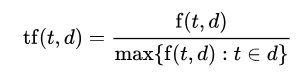
Para la frecuencia inversa de documento dividí el número total de candidatos (10) sobre la cantidad de candidatos que utilizan la palabra que se está analizando y tomando el logaritmo de esa división
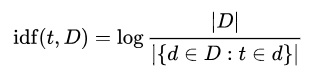
Para finalizar la frecuencia del término teniendo en cuenta el inverso de la frecuencia del documento se calcula como la multiplicación de los otros dos.
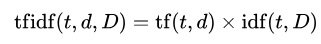

Dime con quién andas…
En twitter generalmente se retuitea material de otro, se lo menciona, se lo cita. Apliqué la misma técnica que expliqué en el punto anterior para ver a qué otras cuentas referencian más los candidatos, teniendo en cuenta tf-idf para ver en las que se diferencian más y no ver citas que compartan mucho:
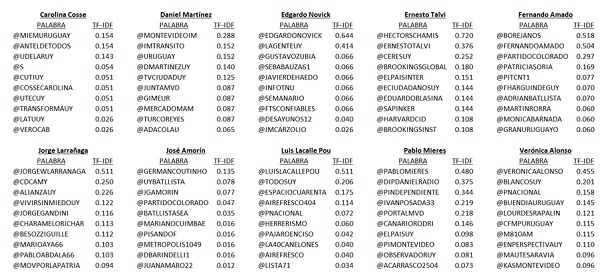
En una futura publicación en vez de analizar los tuits de los candidatos analizaremos las redes que se conforman de acuerdo a las personas que cada uno sigue.
Consultor en Data Analytics & Information Management