

The Maracanazo in color
72 years after the Maracanazo, for the first time, we see the images in color. We share with you the most impressive images, the most exciting videos, with real expressions, thanks to AI.


Image on the left taken from https://marcapaisuruguay.gub.uy/uruguay-y-el-mundo-despidieron-a-alcides-ghiggia-el-uruguayo-que-enmudecio-el-maracana-en-1950/ | Image on the right generated by the author
Within what Artificial Intelligence is, there is a (not so) new concept that is Adversarial/Antagonistic Generative Networks (or GANs for its acronym).
The original paper was presented by Goodfellow et at. in 2014 where they explain what the concept is based on. Basically it is a model to create new “things” and for this they train two models.
These models are nothing more and nothing less than deep neural networks that are trained by backpropagation. The first model is actually the generator and the second is a discriminator that tries to guess if the sample being passed to it is real or dummy (generated by the first model).
.
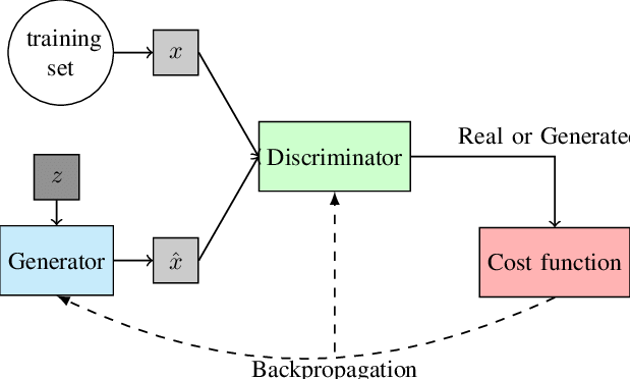
Image taken from Everything You Wanted to Know about Deep Learning for Computer Vision but Were Afraid to Ask (Ponti, 2017))
To bring it down to earth, nothing better than an example, suppose that each model is two different people, one trying to learn to fake paintings by a certain artist and the other trying to distinguish if a painting that is shown to him is a fake or if it is real. The information on whether the expert was correct is known by both the expert and the forger and it is thus that both improve in their tasks. The forger is making more and more realistic pictures and the expert is also becoming better at distinguishing. This is the “antagonistic” mechanism that makes both learn.


Imagen on the left taken from: http://elaguante.uy/tag/obdulio-varela/ | Image on the right generated by the author
The idea of GANs, apart from being very innovative, has a lot of applications. Being an unsupervised generative model, new items can be created from a set of similar items, be it face photos, melodies, or whatever. A classic example is https://thispersondoesnotexist.com/ where every time we refresh the browser it shows us a hyper realistic face of a person that doesn’t exist. It also works for art, cats, etc.
Although originally the GANs are unsupervised and the images are generated from noise (the generator does not know the real data but rather learns from what the discriminator answers), later supervised forms were created. That is, some prior knowledge is given to the network, such as a doodle, so that it generates the image from that. Another widely seen case based on this same principle is using photos of horses and transforming them into zebras.
This opened a world of possibilities in terms of image-to-image translation, for example:
- Translation of satellite images to Google maps
- Image translation from day to night
- Translation from photo to artistic painting
- Photo translation from young to old
- Reconstruction of damaged photos
- Translation of black and white images to color images


Image on the left taken from https://www.bbc.com/mundo/noticias/2014/06/140611_wc2014_brasil_1950_uruguay_obdulio_gl | Image on the right generated by the author
But it didn’t stop there, it was also possible to train GANs to generate realistic images from a textual description (in natural language) of what was intended to be seen in the image! Later, based on this idea, other types of architecture were created that gave way to DALLE, Party, Imagen, etc.
The most obvious application that GANs have is that of data augmentation. Obtaining data to train models is usually expensive and difficult, so using this strategy we could generate much more from relatively little data. Having more data has shown a performance gain.
A typical use case for this is for quality control, generating false but realistic images, through alterations, for example, for industrial parts.
It can also be useful for privacy issues. A company may not want to (or legally be unable to) give out customer data because it is confidential or sensitive data (financial, medical records, etc.). However, sometimes it is necessary to share them with third parties (researchers, for example). By generating synthetic data, we will be able to share a general idea about the information, but without sharing any exact sensitive data.

Image on the left taken from http://www.libreexpresion.net/hace-71-anos-nacia-una-marca-registrada-el-maracanazo/ | Image on the right generated by the author


Image on the left taken from https://www.marca.com/reportajes/2010/02/brasil_1950/2010/02/26/seccion_01/1267145745.html | Image on the right generated by the author


Image on the left taken from http://historiaenestampas.blogspot.com/2014/06/el-maracanazo.html | Image on the right generated by the author


Image on the left taken from https://diarioroatan.com/el-mundo-recuerda-70-anos-del-maracanazo-obtenido-por-uruguay/ | Image on the right generated by the author


Image on the left taken from https://www.futbolred.com/selecciones-nacionales/a-16-dias-del-mundial-obdulio-varela-capitan-de-uruguay-en-el-maracanazo-84789 | Image on the right generated by the author
Although the color images I think are original, since I tried to find not only iconic images of the maracanazo but also rarer images, it surely will not surprise many. There have already been people who “colored” images of the last World Cup won by Uruguay, although I suppose it was done by hand, with image editors, and not using artificial intelligence.
What is perhaps a little more original and less seen is to see videos of the time in color. I used a pre-trained model that can be consumed via a Python library called DeOldify (https://github.com/jantic/DeOldify) and two videos I found on YouTube: https://www.youtube.com/watch?v=I3Nxq2nUgFA (Uruguay champion 1950 – THE GOALS) andhttps://www.youtube.com/watch?v=6pMmRFKKZfk (The day Brazil cried | Uruguay World Champion 1950). The credits and rights of the videos and the song belong to their respective authors.
I leave here the results:
Section for nerds
The training of the model has some special features that are beyond the training of “traditional” GANs.
There is one step that is important so that it is used to stabilize the video a bit more so that there are no weird jumps or things like that. All this considering that what is actually being done is to color frame by frame and that no temporality management is done, so it could perfectly happen that an object that is painted green one second appears yellow the next.
A related aspect to this is the use of resnet101 as the backbone of the generator. This network is composed of 5 blocks of 9, 69, 12 and 9 convolutional layers respectively. This architecture has proven to be “easier” to train than very deep networks since, as it is residual, it has shortcuts to skip layers (this avoids some problems such as the vanishing gradient) but at the same time it achieves very good levels of performance in tasks such as picture classification.
The ingenious thing about the training is that instead of training as an ordinary GAN, the generator is first trained in a conventional way. For this I provide you with color training images that are transformed to black and white. It uses a loss to adjust the weights so that they can generate color images from the black and white images.
The discriminator is then trained: it is fed with the images generated by the generator and real images and is trained as a run-of-the-mill binary classifier.
Finally (with between 1 and 3% of the dataset images) the generator and discriminator are trained together with a traditional GANs approach. This part of the training is very similar to a two-player minimax game: the generator tries to maximize the chance that the discriminator will make mistakes, and the discriminator tries to minimize its error. The final model, implemented in PyTorch, weighs about 900MB and although when the video quality is not very good the colors are a bit “washed out” it fulfills its purpose very well and when the videos are in black and white, but good quality they are impeccable.