

El color del Maracanazo
A 72 años del maracanazo por primera vez vemos las imágenes a color. Compartimos con ustedes las imágenes más impactantes, los videos más emocionantes, con expresiones reales, gracias a la inteligencia artificial.


Imagen en blanco y negro extraída de https://marcapaisuruguay.gub.uy/uruguay-y-el-mundo-despidieron-a-alcides-ghiggia-el-uruguayo-que-enmudecio-el-maracana-en-1950/ | Imagen a color generada por el autor
Dentro de lo que es la Inteligencia Artificial hay un concepto (no tan) nuevo que son las Redes Generativas Adversarias/Antagónicas (o GANs por su sigla en inglés).
El paper original lo presentó Goodfellow et at. en 2014 donde explican en qué se basa el concepto. Básicamente es un modelo para crear “cosas” nuevas y para esto entrenan dos modelos.
Estos modelos son nada más y nada menos que redes neuronales profundas que se entrenan mediante backpropagation. El primer modelo es realmente el generador y el segundo es un discriminador que intenta adivinar si la muestra que se le está pasando es real o es ficticia (generada por el primer modelo).
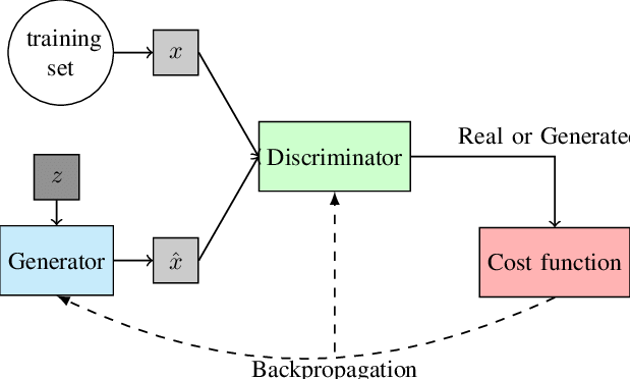
Imagen extraída de Everything You Wanted to Know about Deep Learning for Computer Vision but Were Afraid to Ask (Ponti, 2017)
Para bajarlo a tierra nada mejor que un ejemplo, supongamos que cada modelo son dos personas distintas, una que intenta aprender a falsificar cuadros de un determinado artista y el otro que intenta distinguir si un cuadro que se le muestra es una falsificación o si es real. La información sobre si el experto acertó la conoce tanto el experto como el falsificador y es así que ambos van mejorando en sus tareas. El falsificador cada vez hace cuadros más realistas y el experto también cada vez es mejor distinguiendo. Este es el mecanismo “antagónico” que hace que ambos aprendan.


Imagen a blanco y negro extraída de http://elaguante.uy/tag/obdulio-varela/ | Imagen a color generada por el autor
La idea de las GANs, además de ser muy innovadora, tiene un montón de aplicaciones. Al ser un modelo generativo no supervisado, se pueden crear elementos nuevos a partir de un conjunto de elementos similares ya sean fotos de caras, melodías o lo que fuera. Un ejemplo ya clásico es https://thispersondoesnotexist.com/ donde cada vez que refrescamos el navegador nos muestra una cara hiper realista de una persona que no existe. También existe para arte, gatos, etc.
Si bien originalmente las GANs son no supervisadas y las imágenes se generan a partir de ruido (el generador no conoce los datos reales sino que va aprendiendo por lo que el discriminador le va contestando) luego se crearon formas supervisadas. Es decir, se le dan algunos conocimientos previos a la red, como un garabato, para que genere la imagen a partir de eso. Otro caso muy visto basado en este mismo principio es usar fotos de caballos y transformarlos a cebras.
Esto abrió un mundo de posibilidades en lo que es traducción de imagen a imagen, por ejemplo:
- Traducción de imágenes satelitales a Google maps
- Traducción de imágenes de día a noche
- Traducción de foto a pintura artística
- Traducción de foto de joven a viejo
- Reconstrucción de fotos dañadas
- Traducción de imágenes a blanco y negro a imágenes a color


Imagen a blanco y negro extraída de https://www.bbc.com/mundo/noticias/2014/06/140611_wc2014_brasil_1950_uruguay_obdulio_gl | Imagen a color generada por el autor
¡Pero no se quedó ahí, también fue posible entrenar GANs para que generaran imágenes realistas a partir de una descripción textual (en lenguaje natural) de lo que se pretendía ver en la imagen! Luego sobre esta idea se fueron creando otro tipo de arquitecturas que dieron paso a DALLE, Party, Imagen, etc.
La aplicación más obvia que tienen las GANs es la de la data augmentation. Conseguir datos para entrenar modelos suele ser costoso y difícil por lo que mediante esta estrategia podríamos a partir de relativamente pocos datos generar muchísimos más. El tener más datos ha demostrado una ganancia de rendimiento.
Un caso de uso típico de esto es para control de calidad, generando imágenes falsas pero realistas, mediante alteraciones, por ejemplo, para piezas industriales.
También puede ser útil por temas de privacidad. Una empresa puede no querer (o legalmente estar imposibilitada de) dar datos de sus clientes por ser datos confidenciales o sensibles (registros financieros, médicos, etc.). Sin embargo, a veces es necesario compartirlos con terceros (investigadores, por ejemplo). Generando datos sintéticos podremos compartir una idea general sobre la información, pero sin compartir ningún dato confidencial exacto.

Imagen en blanco y negro extraída de http://www.libreexpresion.net/hace-71-anos-nacia-una-marca-registrada-el-maracanazo/ | Imagen a color generada por el autor


Imagen en blanco y negro extraída de https://www.marca.com/reportajes/2010/02/brasil_1950/2010/02/26/seccion_01/1267145745.html | Imagen a color generada por el autor


Imagen en blanco y negro extraída de http://historiaenestampas.blogspot.com/2014/06/el-maracanazo.html | Imagen a color generada por el autor


Imagen en blanco y negro extraída de https://diarioroatan.com/el-mundo-recuerda-70-anos-del-maracanazo-obtenido-por-uruguay/ | Imagen a color generada por el autor


Imagen en blanco y negro extraída de https://www.futbolred.com/selecciones-nacionales/a-16-dias-del-mundial-obdulio-varela-capitan-de-uruguay-en-el-maracanazo-84789 | Imagen a color generada por el autor
Si bien las imágenes a color creo que son originales, ya que intenté no solo buscar imágenes icónicas del maracanazo sino también imágenes más raras, seguramente no sorprenda a muchos. Ya hubo gente que “colorizó” imágenes del último mundial ganado por Uruguay, aunque supongo que fue a mano, con editores de imágenes, y no usando inteligencia artificial.
Lo que quizás si sea un poco más original y menos visto es ver videos de la época a color. Utilicé un modelo ya entrenado que se puede consumir mediante una librería en Python llamada DeOldify (https://github.com/jantic/DeOldify) y dos videos que conseguí en YouTube: https://www.youtube.com/watch?v=I3Nxq2nUgFA (Uruguay campeón 1950 – LOS GOLES) y https://www.youtube.com/watch?v=6pMmRFKKZfk (El día que Brasil lloró | Uruguay Campeón del Mundo 1950). Los créditos y derechos de los videos y de la canción es de sus respectivos autores.
Les dejo por acá los resultados:
Sección para nerds
El entrenamiento del modelo tiene algunas particularidades especiales que escapan a lo que es el entrenamiento de GANs “tradicionales”.
Hay un paso que es importante para que se utiliza para estabilizar un poco más el video y que no haya saltos raros o artefactos. Todo esto teniendo en cuenta que en realidad lo que se está haciendo es colorear frame a frame y que no se hace ningún manejo de temporalidad por lo que perfectamente podría pasar que un objeto que un segundo está pintado de verde al otro aparezca de amarillo.
Un aspecto relacionado con esto es el uso de resnet101 como backbone del generador. Esta red está compuesta por 5 bloques de 9, 69, 12 y 9 capas convolucionales respectivamente. Esta arquitectura ha demostrado ser más “fácil” de entrenar que redes muy profundas ya que como es residual tiene atajos para saltearse capas (esto evita algunos problemas como el vanishing gradient) pero a su vez logra muy buenos niveles de performance en tareas como la clasificación de imágenes.
Lo ingenioso del entrenamiento es que en vez de entrenar como una GAN común y corriente primero se entrena el generador de manera convencional. Para esto se lo proveé de imágenes de entrenamiento a color que se transforman a blanco y negro. Utiliza una loss para ajustar los pesos y que sean capaces de a partir de las imágenes en blanco y negro generar las imágenes a color.
Luego se entrena el discriminador: se lo alimenta con las imágenes generadas por el generador e imágenes reales y se entrena como un clasificador binario común y corriente.
Por último (con entre un 1 y un 3% de las imágenes del dataset) se entrenan el generador y el discriminador juntos con un enfoque tradicional de GANS. Esta parte del entrenamiento es muy similar a un juego de minimax de dos jugadores: el generador trata de maximizar la posibilidad de que el discriminador cometa errores y el discriminador minimizar su error.
El modelo final, implementado en PyTorch, pesa cerca de 900MB y si bien cuando la calidad del video no es muy buena los colores quedan un poco “lavados” cumple muy bien con su propósito y cuando los videos son en blanco y negro, pero de buena calidad quedan impecables.