

Episode IV – A New Algorithm
En el tercer artículo que escribí sobre este tema dije que iba a ser el último. Mentí. Es que la famosa aplicación sigue dando tela para cortar y se preguntarán porqué.
Tuve la suerte de que Juan Pablo Blanco (el que ideó la aplicación y uno de sus creadores) leyó mis posts y le gustaron.
Empezamos a escribirnos por Twitter e intercambiar ideas sobre el algoritmo en particular, sobre la IA en general y sobre distintos usos que se le puede dar a este tipo de metodologías. También hablamos sobre proyectos a realizar en conjunto y nos colgamos tanto que quedamos en juntarnos para seguir debatiendo.
El encuentro
Fue así como quedamos de vernos en “Cafés de DATA” una meetup organizada por Cívico y DATA Uruguay . Este tipo de encuentros es básicamente una reunión para compartir ideas vinculadas a los datos abiertos.
Esta edición se trató sobre generar herramientas y proyectos que involucren datos de cara a las próximas elecciones. La actividad estuvo dentro del marco de iniciativas a nivel mundial por la Semana del Gobierno Abierto (Open Gov Week) con el objetivo de generar herramientas de tecnología cívica que sean de utilidad para informarse, seguir y entender mejor el proceso electoral.

En la reunión surgieron varias ideas muy interesantes como por ejemplo:
• “Elegi Legi”: te proponen las últimas 30 leyes que votó el parlamento, vos votás, y te compara lo que vos votaste con cómo votaron los actuales diputados y senadores. La idea está buena porque creo que a todo el mundo le interesaría saber qué votan los legisladores pero, aunque parezca mentira, no se puede acceder fácilmente a esa información en Uruguay.
• Combatir fake-news con datos: ej.: uycheck.com
• Cargografías: es una línea de tiempo que muestra los cargos que tuvo cada diputado/senador/ministro/etc. a lo largo de su vida. Es una forma de visualizar todo el currículum para ver cómo se van moviendo tanto en el sector privado como en el gobierno.
• Declaraciones Patrimoniales: análisis de la declaración jurada de bienes e ingresos de los representantes
• Análisis de jingles: aplicar técnicas de text analytics a los jingles políticos
• Declaración de principios: proponerle a los candidatos al legislativo firmar un compromiso para abrir el parlamento y que se pueda acceder más fácilmente a la información
• Aquienvoto.uy 2.0: que en vez de que te recomiende de acuerdo a lo que piensa la gente parecida a vos, que te de la similitud de tu ideología con la de los candidatos. Para esto se debería hacer un nuevo set de preguntas, que las contesten los candidatos, etc.
Luego de terminada la reunión nos quedamos con Juan Pablo y con Rodrigo Conde (otro de los desarrolladores de aquienvoto.uy) charlando un poco más en profundidad.

Cambio de Modelo
Hace poco había visto un tuit donde comentaban que habían cambiado el algoritmo de la app.
Le consulté a Juan Pablo sobre el nuevo modelo y demás. Como hice en mi primer post con KNeighbors ahora intentaré explicar cómo funciona el algoritmo Logistic Regression.
La regresión logística está dentro de los algoritmos de clasificación y, contrariamente a como funciona la regresión lineal, sirve para predecir datos discretos (no continuos), funciona tanto para predecir resultados binarios (0 o 1, si o no, enfermo o sano, etc.) y también para el caso de clasificar información en múltiples clases.
Por ejemplo, se puede predecir si una persona tendrá una reacción adversa a una droga, si va a estar nublado, soleado o lluvioso, etc. Para la regresión logística el objetivo no es predecir un número real. Como se ve en el ejemplo del clima, también es importante destacar que la etiqueta no tiene porqué ser binaria pero sí es un número finito de etiquetas.
No le pregunté a los muchachos sus razones particulares sobre porqué cambiaron el modelo pero me animo a arriesgar algunos motivos.
Defectos de KNeighbors
El algoritmo anterior, conocido como el del vecino más cercano, es muy bello por su simpleza y sencillez, tanto es así que cualquier persona –aunque no sea informático- se puede hacer una idea en segundos sobre cómo funciona. Esta característica también considero que es uno de sus defectos principales.
Para algunos casos es demasiado trivial, de hecho no aprende nada, la parte de machine learning es muy básica, la computadora lo único que tiene que hacer es recordar. La máquina «memoriza» los datos de entrenamiento y cuando queremos predecir la etiqueta de un nuevo ejemplo buscamos el ejemplo más cercano dentro de los datos de entrenamiento y suponemos que debería pertenecer a la misma categoría.
El mayor problema con este algoritmo es el ruido (noise), que es cuando tenemos mal clasificada la información de entrenamiento, ya que si el vecino más cercano está mal entonces voy a clasificar mal a la nueva instancia. Para intentar mitigar este problema se suele buscar los K vecinos más cercanos y seleccionar la etiqueta con mayor frecuencia.
La determinación de ese K, de la cantidad de vecinos que voy a tener en cuenta es todo un tema.
Para que se entienda bien vamos a llevarlo a la vida real: supongamos que queremos predecir a quién va a votar una persona y supongamos que esta persona vive en Arocena y Rivera, a media cuadra del Carrasco Lawn. Puedo tocarle el timbre al vecino que viva más cerca y preguntarle a quién va a votar. Ese vecino podría bien ser un votante del Frente Amplio (el 20,43% de las personas de Carrasco lo hace) o del Partido Colorado (20,39% de ese barrio son votantes del partido de Batlle y Ordoñez). Pero si en vez de tener en cuenta al vecino más cercano tenemos en cuenta a los 10 vecinos más cercanos y vemos a qué partido votan la mayoría de esos 10, seguramente la predicción nos dé que votará al Partido Nacional, ya que el 48,9% de las personas que viven en Carrasco así lo hace. Siguiendo con el razonamiento, si extendemos la cantidad de vecinos a considerar y tomamos 1.5M de vecinos más cercanos, la predicción nos dará que va a ser votante del FA, ya que el partido de gobierno en la capital tiene una adhesión del 53,51%.
Se ve en ese ejemplo que si seleccionamos un K muy grande el resultado va a estar fuertemente influenciado por el tamaño de las clases. Si en los datos de entrenamiento tenemos muchos más frenteamplistas que ningún otro y elegimos un K muy grande va a tender a salir siempre eso. Probablemente eso fue lo que le pasó a aquienvoto, el que tenía más era Talvi y por eso a muchos les salía siempre ese candidato.
Si bien el aprendizaje en KNN es muy rápido, ya que simplemente hay que memorizar todo y no se requiere matemática, la desventaja es que si yo tengo millones de ejemplos y los tengo que guardar todos consume mucha memoria. Otra desventaja es que cada vez que quiero hacer una predicción puede llevar mucho tiempo porque habría que hallar la distancia del caso que se quiere predecir contra todos los que tengo, ese es el precio a pagar de no tener overhead en el pre-procesamiento (si bien obviamente hay algoritmos mejores que la fuerza bruta para aproximarse a los K vecinos más cercanos).
Por otro lado no estamos obteniendo información sobre el proceso y tampoco tenemos realmente un modelo como por ejemplo cuando se hace una regresión lineal.
Luego de haber presentado todas las que para mí son desventajas del anterior modelo, voy a tratar de explicar el nuevo método, que es probablemente el método más común utilizado en machine learning: la regresión logística.
Regresión Logística
Como ya se comentó más arriba, la regresión logística es en alguna forma similar a la regresión lineal pero distinta en algunos aspectos cruciales. La regresión lineal se usa para predecir un número real, en este caso lo que queremos es la probabilidad de que un evento ocurra. Es decir, sabemos que la variable dependiente puede tener solo un conjunto finito de valores posibles (por ejemplo los posibles candidatos a presidente). El problema con la regresión lineal es todo el tiempo en el que se obtienen predicciones que no tienen sentido, no se puede votar mitad a un candidato y mitad a otro, o tener 1/3 de enfermedad. Alguien podría decir que como estamos hablando de probabilidades si el resultado da 0.5 puede querer decir que hay un 50% de chances de que vote a un determinado candidato y no que va a votar a medio candidato, pero si vemos un poco más allá en una regresión lineal podría dar valores mayores a 1 o menores a 0 y eso si no tiene sentido si estamos hablando de probabilidades.
Lo que hace la regresión lineal es encontrar lo que se conoce como el peso de cada característica.
Nosotros tomamos cada característica (cada una de las preguntas del formulario) y calculamos para cada una de ellas un determinado peso que es el que vamos a usar para hacer predicciones. Los pesos vienen a ser el correspondiente a los coeficientes cuando estamos haciendo una regresión lineal.
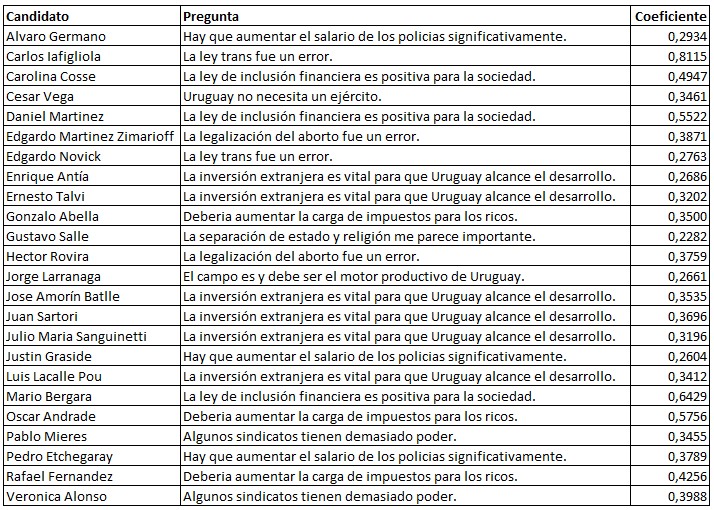
Entonces básicamente tenemos coeficientes asociados a cada variable. Vamos a tomar esos coeficientes, sumarlos, multiplicarlos por algo y hacer una predicción. Un peso positivo implica que esa variable esta positivamente correlacionada con la salida. Por ejemplo, la afirmación «La ley trans fue un error» está positivamente correlacionada con votar a Carlos Lafigliola ¡el coeficiente es 0,8115!
Por otro lado, un peso negativo indica que la variable está negativamente correlacionada a la salida. Entonces la afirmación «Las FF.AA. deberían tener un rol activo en la seguridad pública» tiene un peso negativo (-1,2188) para el caso del candidato Héctor Rovira y por lo tanto está correlacionada negativamente. Es decir, cuanto más de acuerdo estás con esa afirmación más difícil es que puedas ser un votante del coronel retirado. No es absoluto, es solo una correlación.
Una vez entrenado el modelo y hallado los pesos para cada característica, fácilmente se puede introducir un nuevo conjunto de características (respuestas a las preguntas del cuestionario) y el modelo devuelve la probabilidad asociada a cada una de las posibles etiquetas (es decir, la probabilidad asociada a votar a cada uno de los candidatos).
Lo bueno de este algoritmo es que, si bien puede ser lento generar el modelo, una vez que está generado es muy rápido para clasificar, ya que es independiente del tamaño del conjunto de datos que se utilizó para el entrenamiento. Una vez que se tienen los coeficientes es básicamente una evaluación polinómica.
La otra ventaja que considero aún más importante es que arroja insights (hallazgos) sobre las variables. Al tener los coeficientes podemos ver claramente cuáles son las que están más o menos correlacionadas a cada una de las etiquetas. Por ejemplo, en la siguiente tabla vemos la pregunta que está más fuertemente relacionada positivamente a cada candidato:
¿Será la regresión logística el mejor algoritmo para hacer estas predicciones? Estén atentos al próximo artículo.
Consultor en Data Analytics & Information Management