

A New Algorithm, episodio V
@johnblancott Strikes Back
En el artículo anterior comenté entre otras cosas sobre las diferencias entre el primer algoritmo que se usó para hacer las predicciones en aquienvoto.uy que era el KNeighbors y el segundo algoritmo que se utilizó, la Regresión Logística. También dejaba planteada la consulta sobre si este último sería el mejor a la hora de predecir el candidato.
El desafío
Juan Pablo me desafió por Twitter a crear un modelo mejor que el de él:
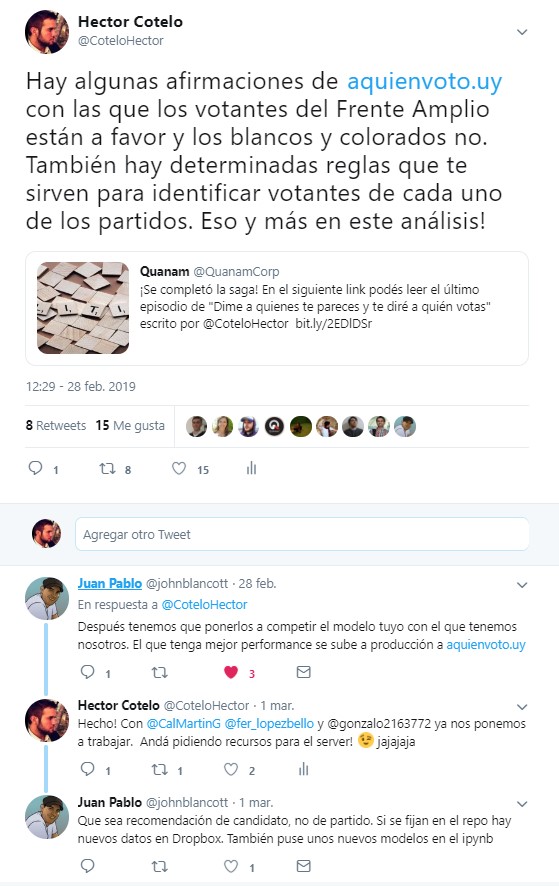
Es bastante común en el mundo del data science hacer competencias entre distintos desarrolladores a ver quién es capaz de crear el algoritmo más performante. Incluso existe la página kaggle donde empresas prestigiosas suben competencias donde distintos equipos compiten por premios millonarios.
Cuando se habla de mejor performance en un modelo de ML se puede hablar de muchas cosas.
Generalmente, cuando uno se refiere a la exactitud de un modelo se refiere al accuracy (que es el porcentaje de predicciones que hace bien) pero a veces no es una medida muy buena. Por ejemplo, en la tragedia del Titanic murieron 812 de 1.300 pasajeros. Podríamos querer hacer un modelo que en función de la clase en la que viajó, el sexo y la edad prediga si un pasajero sobrevivió o no. Supongamos que simplemente, sin importar el valor de las variables independientes, predecimos que el pasajero murió, es decir, siempre, absolutamente para todos los casos, la salida del algoritmo es “murió”. Haciendo eso, voy a tener un modelo con una precisión del 62% para los pasajeros y 76% para los miembros de la tripulación. Usualmente en machine learning si obtenés un 76% es un éxito!
Esto es lo que sucede cuando las clases que se intentan predecir no son balanceadas, y en esos casos la precisión no es una medida muy significativa. Queda más claro aún con un ejemplo de la medicina: hay enfermedades que son muy raras, que le ocurren únicamente al 0.1% de la población, en este caso puedo construir un excelente modelo predictivo que simplemente diga «no, el paciente no tiene la enfermedad» y va a ser muy “accurate” pero totalmente inútil.
Es por eso que también es útil tener en cuenta otras medidas para analizar un modelo. Dos muy importantes son la cobertura (recall o sensivity en inglés) y la precisión (precision o specificity).
La cobertura se calcula de la siguiente manera: imaginemos que en nuestro conjunto de datos de test tenemos 10 personas que votan a X candidato y el modelo de esos 10 predice correctamente a 7 (a los otros tres les asigna –erróneamente- otro candidato), en ese caso la cobertura da 7/10 = 70%.
Para la precisión el ejemplo sería el siguiente: imaginemos que el modelo predice como votantes del candidato X a 9 personas, pero de esos 9 los que efectivamente son votantes del candidato X son 7, entonces 7/9 = 77,77%.
Si yo quiero predecir cáncer de mama seguramente prefiera cobertura a precisión, porque de esta forma me “aseguro” de no perderme ningún caso donde el paciente realmente tenga cáncer, aunque tenga que realizar estudios a más pacientes para confirmarlo. Al aumentar la cobertura se suele reducir la precisión y se suele obtener mayor cantidad de falsos positivos, es el precio a pagar de intentar no perder ningún positivo real, en otras palabras, cubrir a todos.
Sin embargo, si yo lo que tengo que decidir es si hacer o no una cirugía a corazón abierto probablemente ahí pretendo ser muy específico, ya que el riesgo de la cirugía en si es muy alto y no quiero hacérsela a alguien que realmente no la necesite. En ese caso valoraré más la precisión. Al aumentar la precisión me “aseguro” que a los pacientes que el modelo predice que es necesario hacer una cirugía realmente la precisen. Obviamente el precio a pagar es que el modelo puede indicar que alguien no la precisa cuando en realidad sí.
Lo difícil es intentar tener un balance entre estas dos medidas, beneficiar una sobre la otra dependerá del caso concreto.
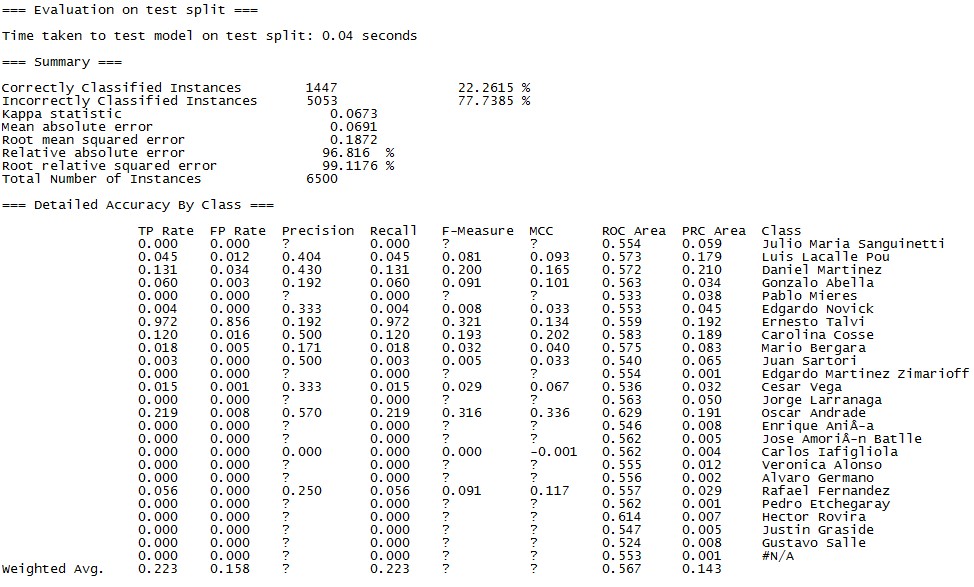
A continuación, van los modelos que probé con sus medidas de exactitud, precisión y cobertura:
Reglas JRip

Árbol de Decisión – J48
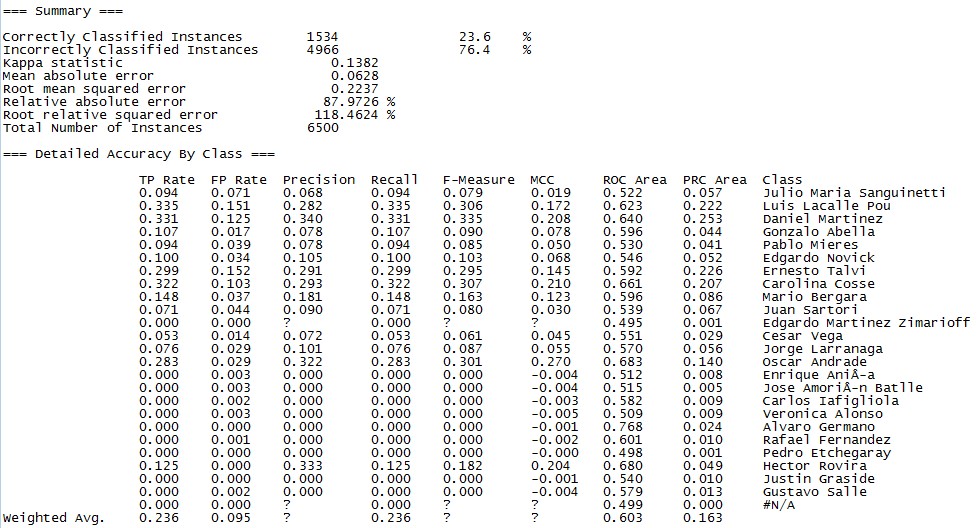
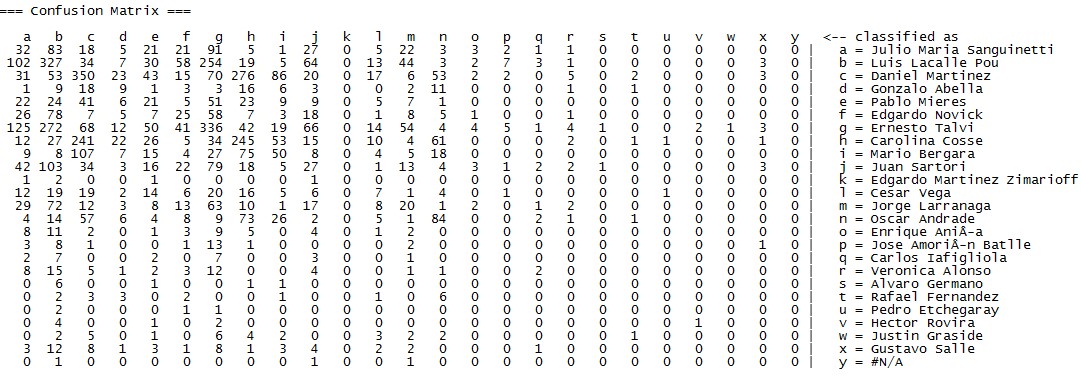
Random Forest
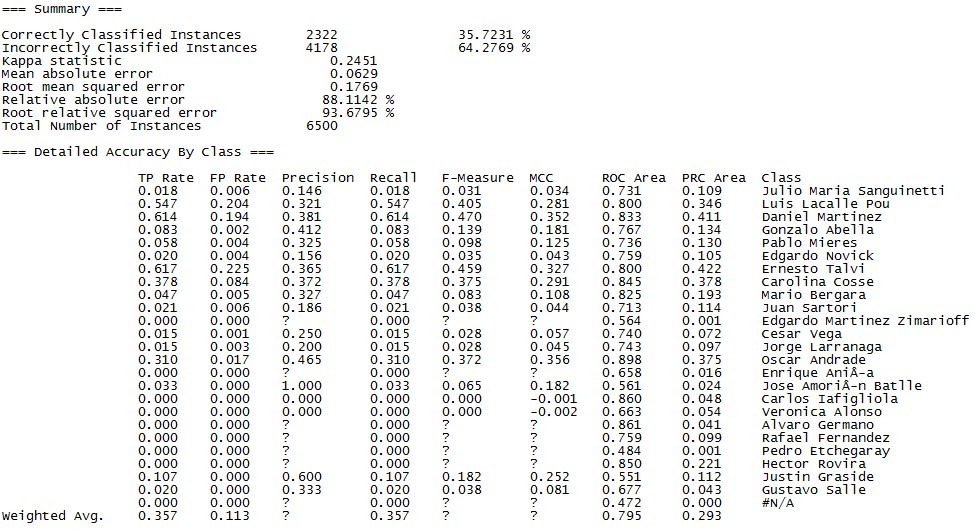

Redes Baysianas (Multinomial)
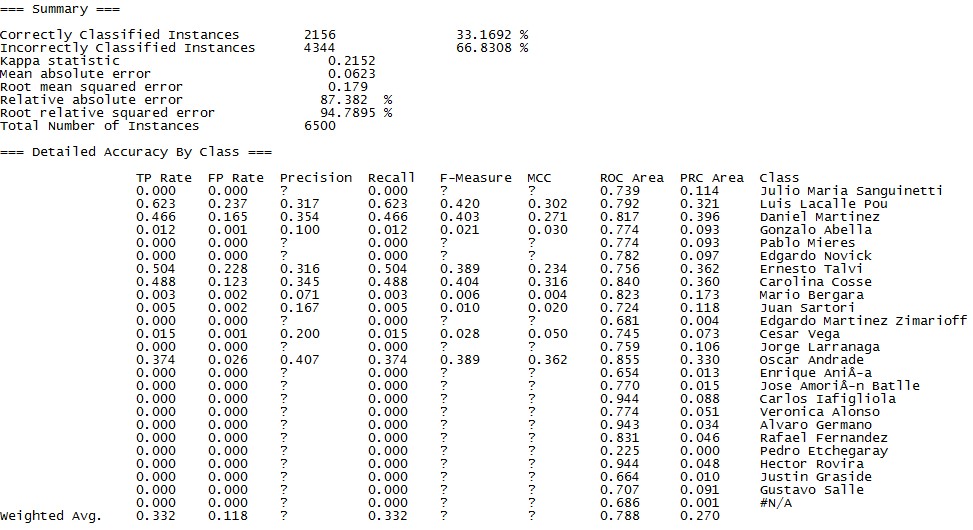
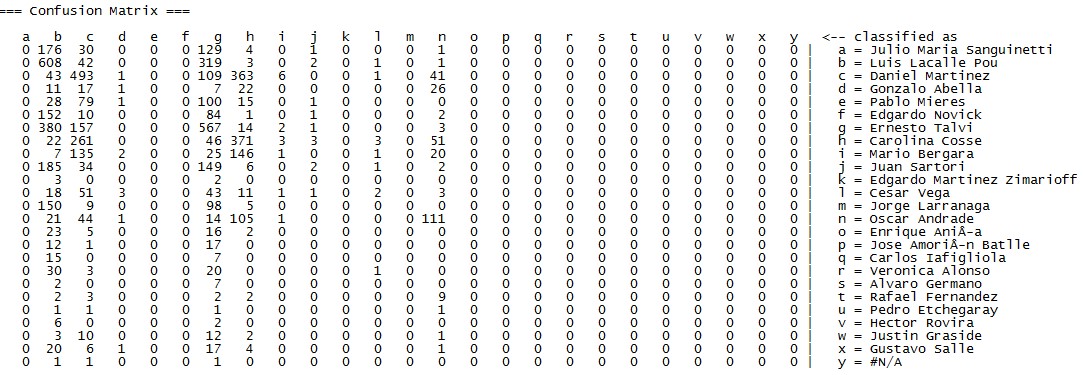
Redes neuronales
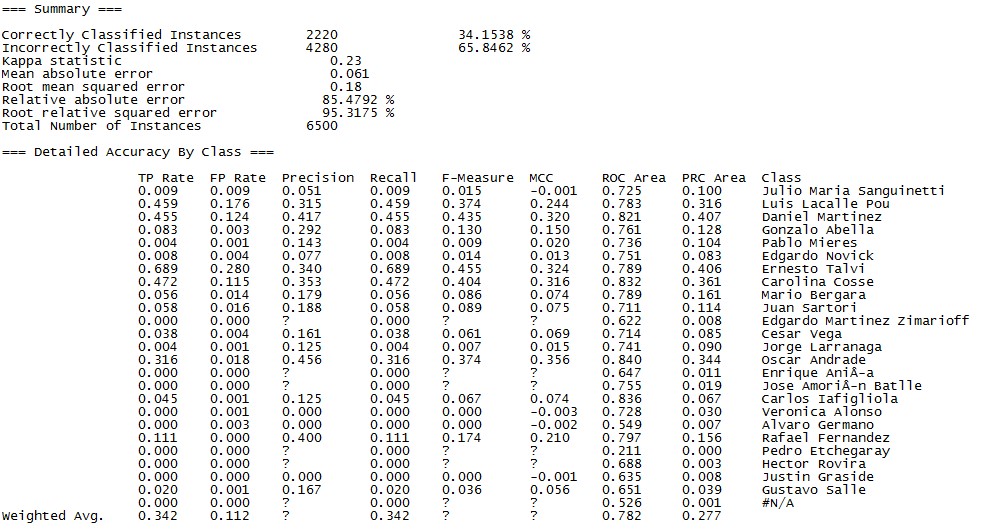

Regresión logística
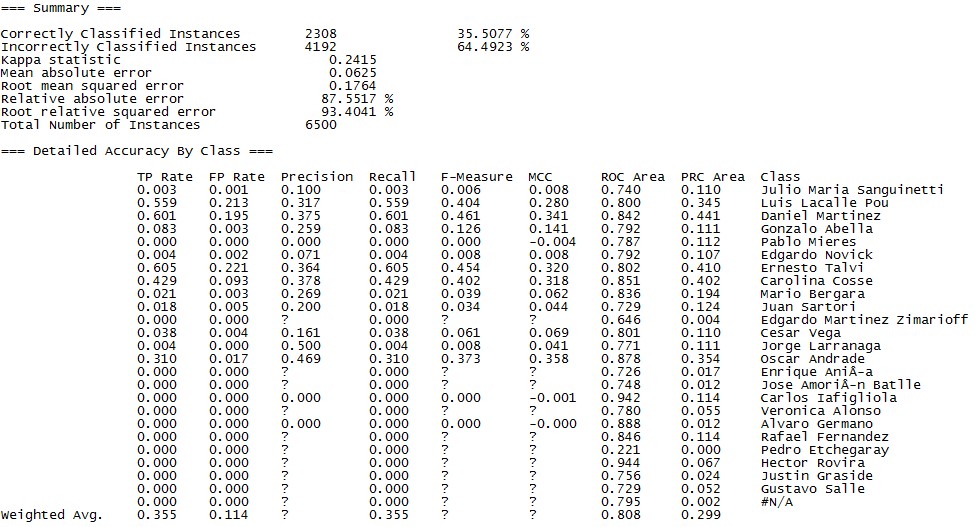

Conclusión
En este caso el modelo que me dio mejores resultados fue el de Random Forest, identificando correctamente 35.72% de los votantes ¿Cómo le está yendo a tu Regresión Lineal, JP?
Consultor en Data Analytics & Information Management