

Dime a quiénes te pareces y te diré a quién votas. Parte III
La semana pasada estalló en las redes, medios de comunicación y charlas entre compañeros de trabajo la aplicación aquienvoto.uy, un test que recomienda al usuario a qué candidato votar en las próximas elecciones.
Básicamente el usuario debe indicar puntuando del 1 al 5 (1 «en desacuerdo», 3 «neutral/no lo sé» y 5 «totalmente de acuerdo») 26 afirmaciones sobre economía, seguridad y sociedad. Con esas respuestas la aplicación indica a qué candidato votar.
En la primera parte de este artículo expliqué con un ejemplo cómo es que funciona el algoritmo. En la segunda parte analicé las respuestas de los usuarios para ver cuál era el partido y el candidato con más “votos” y también cuáles eran las afirmaciones del cuestionario con las que los uruguayos estamos a favor, con las que estamos en contra y las que dividen las aguas.
En esta tercer y última entrega (además de seguir analizando las respuestas de los usuarios) comentaré sobre otros modelos de clasificación que desarrollé, basándome en algoritmos distintos al KNeighborsClassifier.
Mi propio modelo
Se me ocurrió que podía estar bueno generar otro modelo, un árbol de decisión, teniendo en cuenta los datos de las 25.166 personas que al final del formulario respondieron realmente cuál era su candidato preferido. Para esto decidí usar Weka.
Una vez importados los datos al mismo en el perfilamiento primario de los datos surgen cosas interesantes:
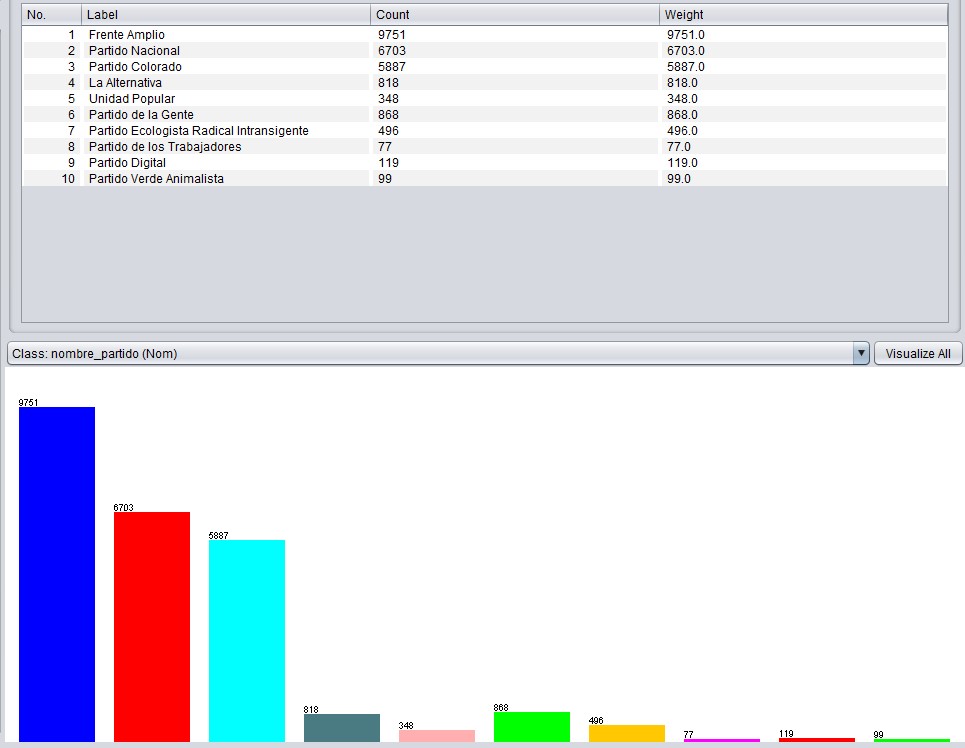
Vemos que al seleccionamos el atributo “debería aumentar la carga de impuestos para los ricos” la barra de la respuesta «totalmente de acuerdo» (5) es casi toda azul que son las personas que indicaron ser votantes del Frente Amplio mientras que en la barra correspondiente a “en desacuerdo” (1) predominan el rojo y el celeste que son los que indicaron votar al Partido Nacional y al Partido Colorado respectivamente.
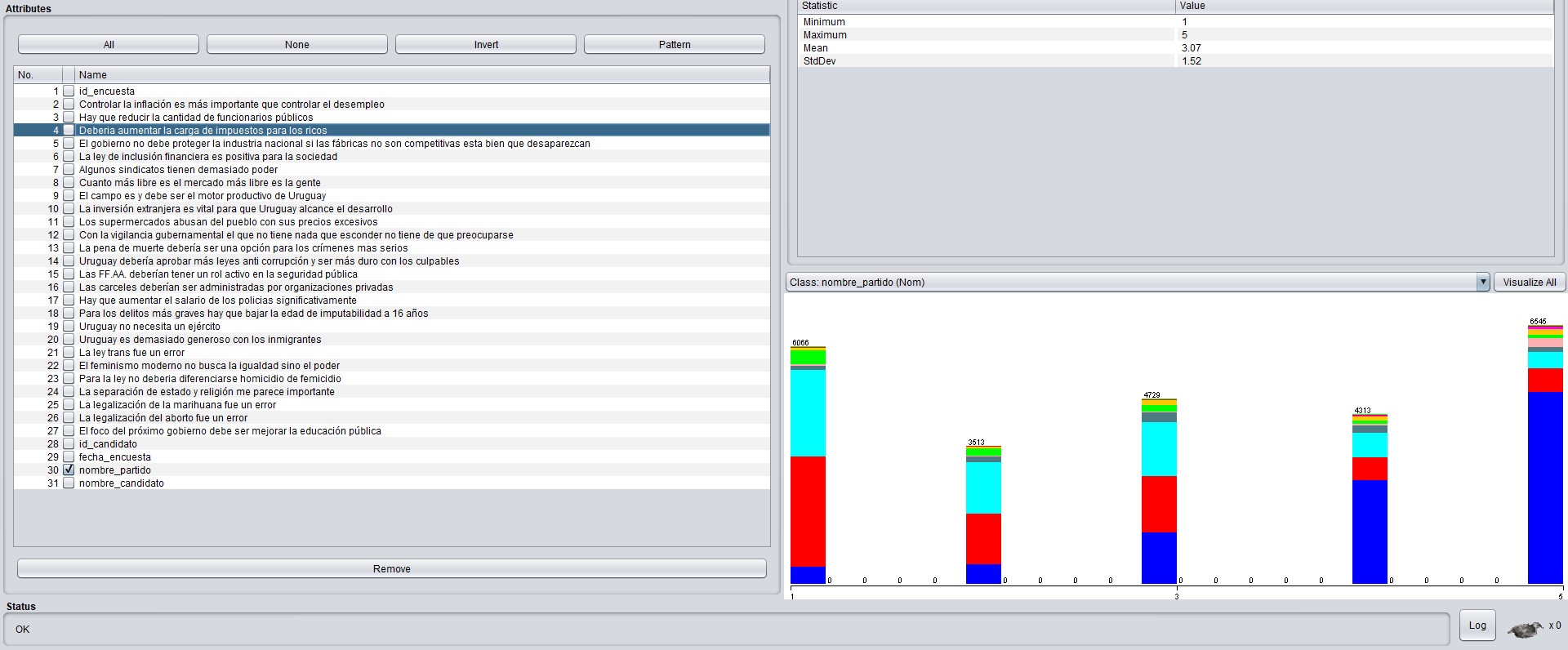
Se da a la inversa si se analizan las respuestas a la afirmación “La legalización de la marihuana fue un error”
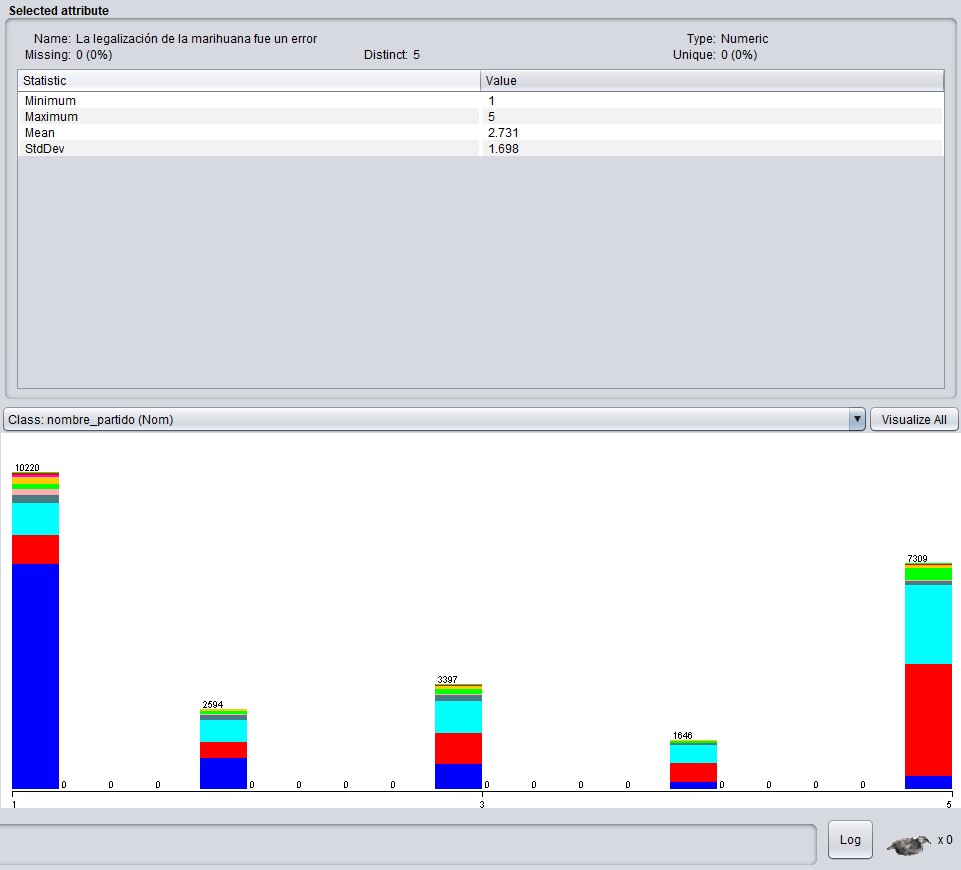
Se ve claramente que la mayoría de los frenteamplistas están de acuerdo con la legalización de la marihuana mientras que la mayoría de los que no están de acuerdo son blancos o colorados.
Pero vamos a lo prometido, el modelo de árbol de decisión, para esto usé un algoritmo llamado Random Forest (bosques aleatorios).
Para probar el modelo seleccioné aleatoriamente el 30% de los registros del conjunto de datos. También para simplificarlo filtré algunos registros y me quedé únicamente con las encuestas en las cuales la persona declaró ser votante del Frente Amplio, del Partido Nacional o del Partido Colorado.
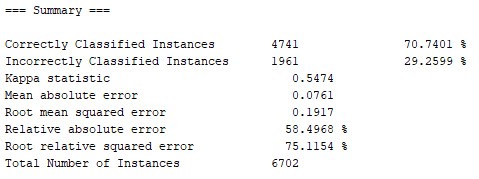
Aquí se ve que de las 6.702 encuestas que se utilizaron para probar el modelo casi un 71% fueron clasificadas correctamente (con 100 iteraciones para la creación del modelo).
En la matriz de confusión vemos como fueron los falsos positivos y negativos:
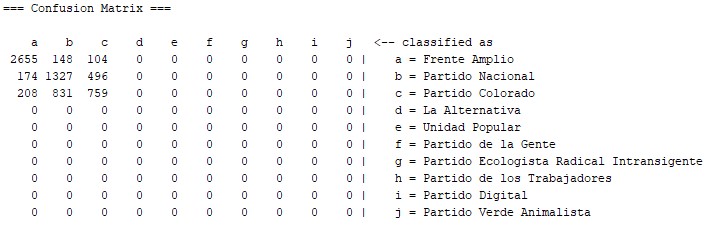
Esta matriz debe leerse como que se clasificaron como frenteamplistas a: 2.655 frenteamplistas, 174 blancos y 208 colorados. Sin embargo, dentro del conjunto de usuarios que indicaron votar al Frente Amplio se clasificaron a 2.655 correctamente, 148 se clasificó como blancos y 104 como colorados.
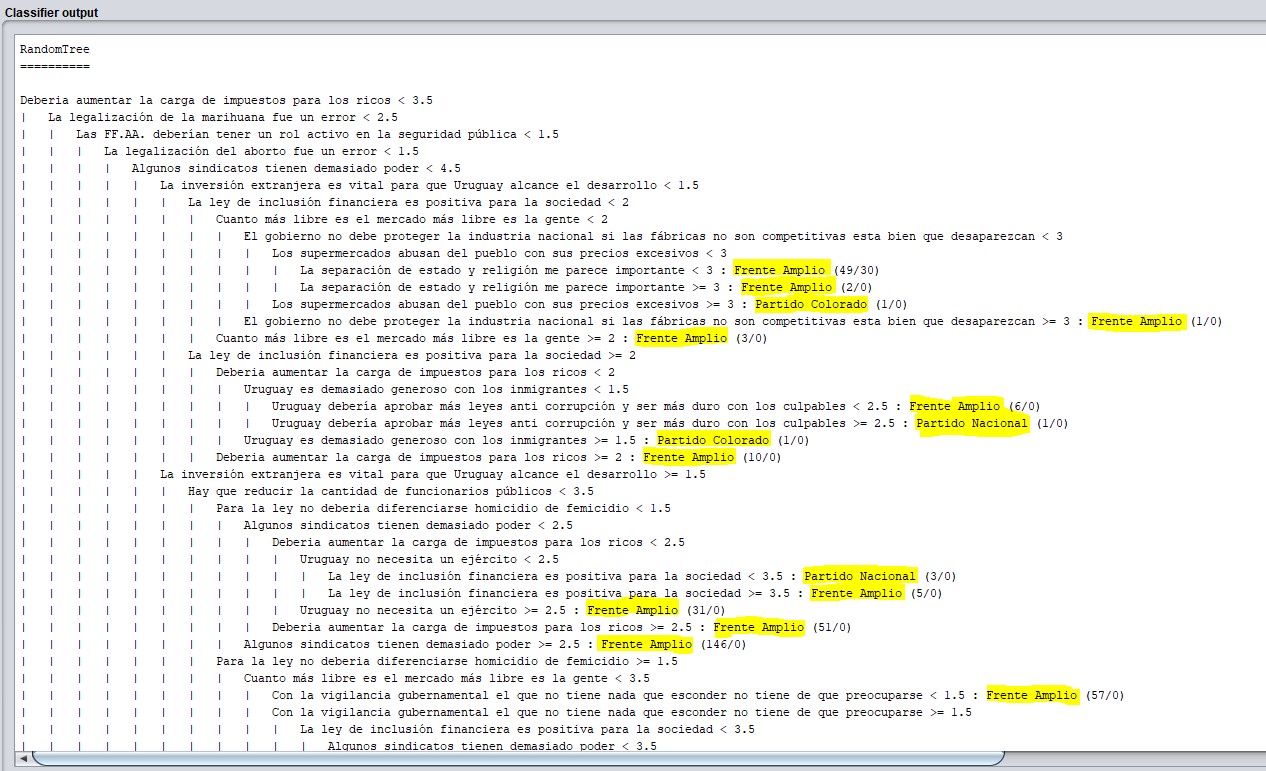
En la siguiente imagen vemos parte del árbol generado:
También, ya que estaba, generé otro modelo, basado en reglas, con el algoritmo JRip. A continuación, les dejo un par de reglas que descubrió el algoritmo y me resultaron interesantes:
Si se cumple que: (Hay que reducir la cantidad de funcionarios públicos = 5) Y (Los supermercados abusan del pueblo con sus precios excesivos <= 3) Y (El foco del próximo gobierno debe ser mejorar la educación pública = 5) Y (La legalización del aborto fue un error <= 4) Y (La legalización de la marihuana fue un error >= 2) Y (Uruguay es demasiado generoso con los inmigrantes <= 2) => es votante del Partido Colorado
Por otro lado, si se cumple que: (La ley trans fue un error >= 3) Y (Las FF.AA. deberían tener un rol activo en la seguridad pública >= 4) Y (El campo es y debe ser el motor productivo de Uruguay = 5) => es votante del Partido Nacional
Conclusiones
Nuevamente vemos aplicaciones novedosas y divertidas a técnicas de machine learning. Agradezco a @johnblancott por la inspiración y sobre todo por compartir los datos de las respuestas y así poder hacer mi propio análisis.
Consultor en Data Analytics & Information Management