

Dime a quiénes te pareces y te diré a quién votas. Parte I
La semana pasada estalló en las redes, medios de comunicación y charlas entre compañeros de trabajo la aplicación aquienvoto.uy, un test que recomienda al usuario a qué candidato votar en las próximas elecciones.
Básicamente el usuario debe indicar puntuando del 1 al 5 (1 “en desacuerdo”, 3 “neutral/no lo sé” y 5 “totalmente de acuerdo”) 26 afirmaciones sobre economía, seguridad y sociedad. Con esas respuestas la aplicación indica a qué candidato votar.
Me habían indicado que estaba basada en “aprendizaje automático” pero no lo creí. Al principio lo que imaginé era que se trataba de una variante del test político que te indica -nuevamente luego de contestar un formulario- en qué parte del Diagrama de Nolan se ubica el que está respondiendo. Creí que, habiendo perfilado a los distintos candidatos, fácilmente el sistema podría indicarnos cuál es el que está más cerquita. De haber sido así, la aplicación no hubiese tenido nada de Machine Learning, Inteligencia Artificial, ni nada por el estilo.
No le di mucha más importancia hasta que descubrí que la aplicación se había viralizado y que había empezado a ser criticada en las redes y en los pasillos. Cuestiones del estilo:
1. Siempre sale Talvi
2. No es transparente, no sabemos quién está detrás ni qué intenciones tiene, cómo configuró el algoritmo, cuánta gente respondió, si hay sesgo, etc.
3. No tiene ninguna confiabilidad, nadie puede votar consistentemente a todo 1 o 5, y sin embargo el algoritmo tira nombres.
4. La encuesta la mandó a hacer el comando de campaña de @dmartinez_uy para robar data
5. No incluyeron al Dr. Salle Lorier
6. Es medio flojón para aprender. Más estadística que otra cosa. Y faltó entrenamiento antes de lanzar
7. Es hackeable, con bots podés hacer que el sistema aprenda que respondas lo que respondas te tiene que sugerir al candidato que vos quieras
8. Es lo mismo que lo que pasó con Facebook & Cambridge Analítica(?)
9. Es antidemocrático(?)
Ante tanto criticón sentí cierta empatía ya que a mí también me criticaron cuando publiqué los resultados del análisis de redes sociales cuando determiné que el Cebolla Rodríguez era el jugador más influyente de la selección o cuando hice el estudio sobre lo que escriben en Twitter los candidatos a presidente del Uruguay (ver aquí) y me interesé sobre el tema.
Entré a la página para investigar un poco y vi que la persona que lleva el proyecto al hombro es Juan Pablo Blanco , no lo conozco, pero ya lo sigo; junto a 2 amigos más. Es un proyecto abierto por lo que tanto el código como el set de entrenamiento y también las respuestas de usuarios están publicados en su repositorio de GitHub.
También aquí se puede ver cómo se fue gestando el proyecto.
Tras leer esa información me di cuenta de que estaba errado, no era una variante del test político, sino que la solución verdaderamente estaba basada en ML, ahí me copé y decidí interiorizarme aún más, sobre todo al ver que tenía a mano el código y los datos!!!
Por eso decidí escribir este artículo, que publicaré en tres partes: la primera explicando cómo funciona el programa desarrollado, la segunda analizando las respuestas de los usuarios y la tercera haciendo yo mismos otros modelos de clasificación utilizando distintos algoritmos.
¿Cómo funciona el programa?
En los siguientes párrafos voy a intentar explicar “en criollo” cómo funcionan este tipo de programas.
Para empezar, hay que aclarar que los candidatos no respondieron el cuestionario. No te dice qué candidato piensa más parecido a vos, sino que te dice a quién votan las personas que piensan parecido a vos.
El programa se basa en un algoritmo conocido como “KNeighborsClassifier” o en español “k vecinos más próximos”. Básicamente es un algoritmo de clasificación de objetos que, a partir de un conjunto de datos inicial, intenta clasificar correctamente todas las instancias nuevas. El set inicial de datos está formado por varios atributos descriptivos (las respuestas a las preguntas) y un solo atributo objetivo (a quién votará).
En concreto los desarrolladores comenzaron con 177 participantes a los que les pidieron que respondieran el formulario ideológico y a su vez les pidieron que respondieran a quién piensan votar en las próximas elecciones. A partir de ese conjunto inicial de datos el programa es capaz de aprender a clasificar nuevas instancias.
¿Cómo? Generalmente lo que se hace para crear el modelo es partir el dataset inicial en dos partes aleatorias: una que se usa para entrenar al modelo, y otra que se usa para validar el modelo creado y ver que tan preciso es.
Claramente, si el modelo es entrenado con respuestas erróneas (por decirlo de alguna manera), aprenderá mal y dará respuestas equivocadas, pero la buena noticia es que a medida que se usa (siempre y cuando al final del cuestionario uno indique su candidato) el modelo se ajusta.
Volviendo al funcionamiento del algoritmo, el modelo creado es básicamente un espacio de vectores n-dimensional con cada una de las respuestas anteriores ya clasificadas, cuando una nueva persona responde el formulario, se representa nuevamente como un vector en ese espacio y el algoritmo selecciona los k vecinos (vectores) más cercanos (de acuerdo con una métrica de similitud escogida). Luego, se fija como están clasificados la mayoría de esos k vectores vecinos y la clasificación que presenta mayor frecuencia es la que se le asigna a la nueva persona.
Vemos que es crucial entonces una correcta determinación de la cantidad de vecinos a tener en cuenta (el famoso valor k) y también la métrica de similitud utilizada. Variaciones en estos aspectos decisivos pueden hacer que el modelo nos de respuestas distintas.
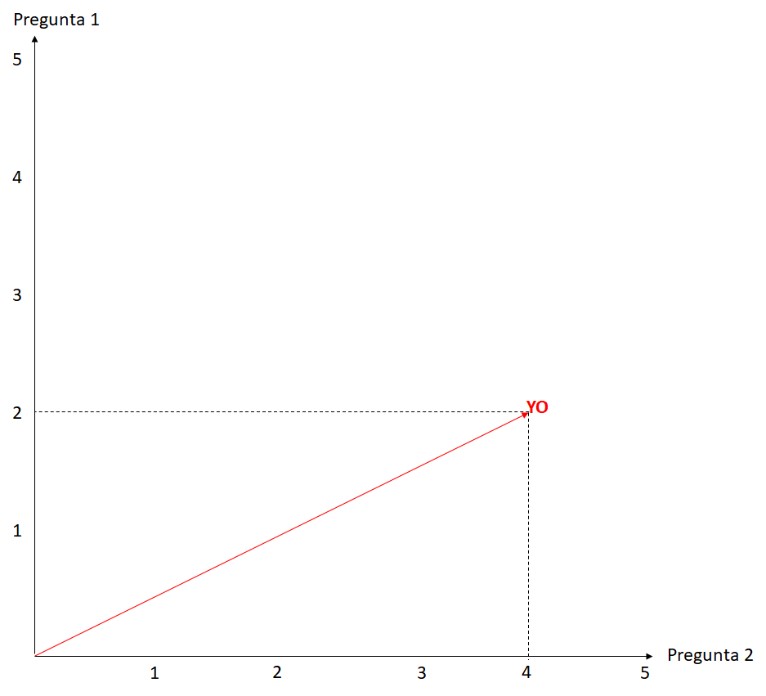
Veamos cómo influye el valor k, vamos a suponer un cuestionario con 2 preguntas para hacerlo más fácil y que se pueda representar claramente en la pantalla. Supongamos que en la primer pregunta respondí 2 y que en la segunda pregunta respondí 4. La aplicación me posicionaría de esta manera:
Sumemos entonces al conjunto de respuestas anteriores, ya clasificadas:
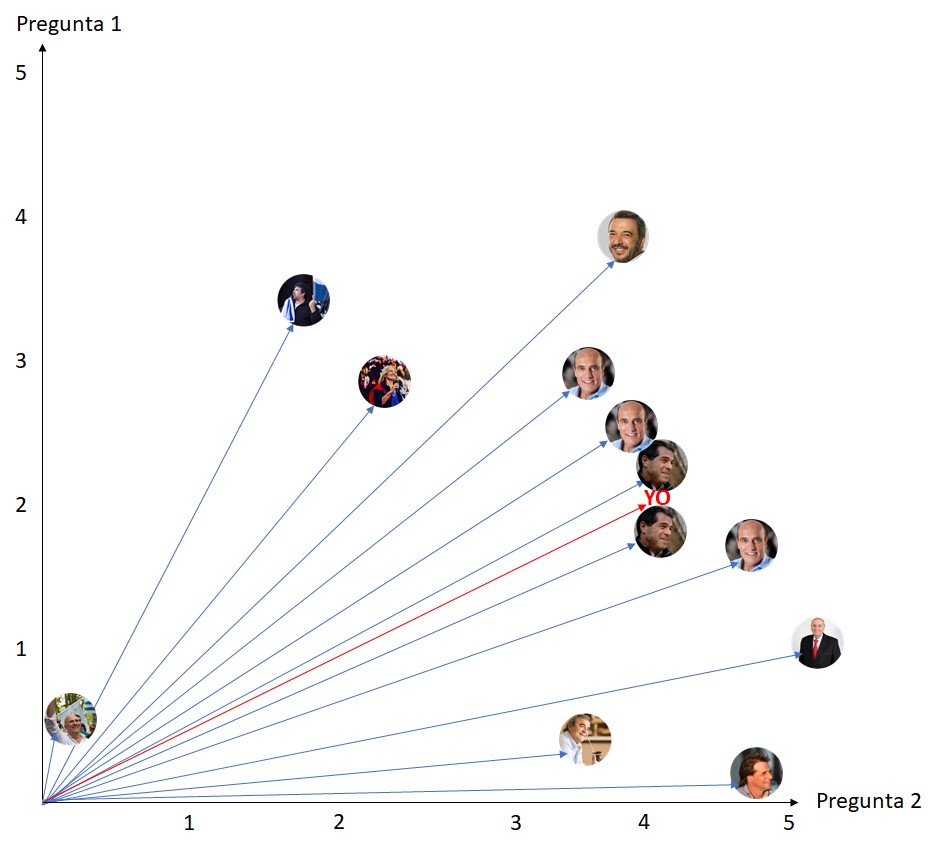
¿Qué pasaría si tomáramos a los dos vecinos más cercanos?
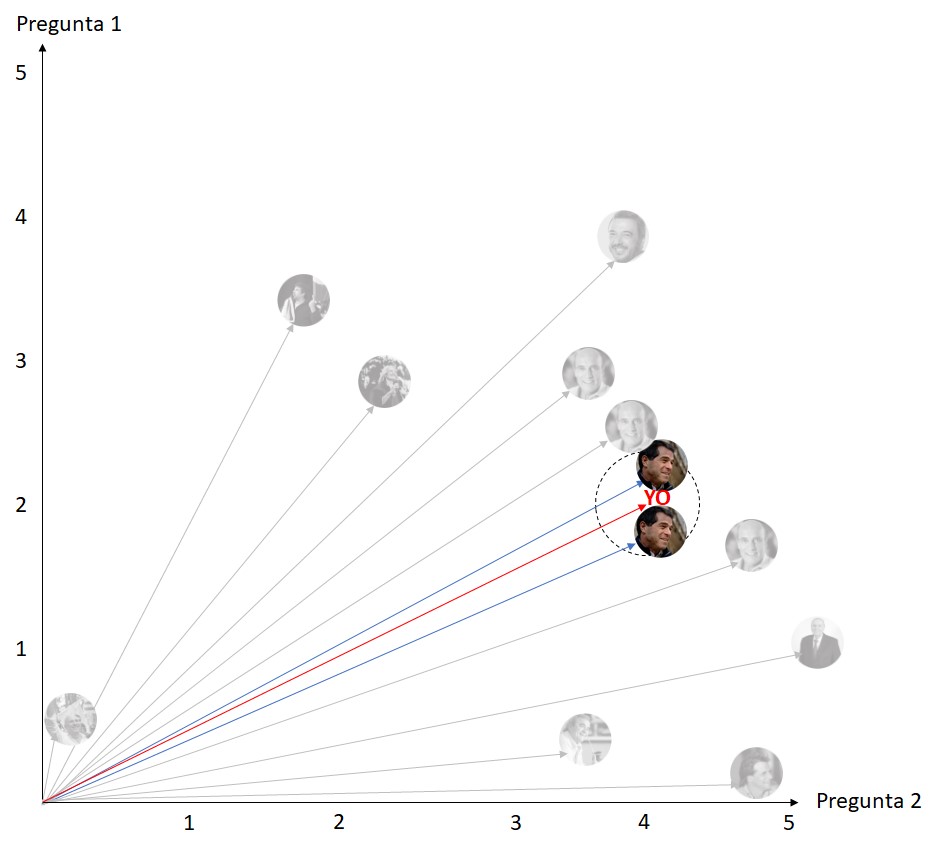
De tener en cuenta únicamente a los dos vecinos más cercanos el algoritmo me diría que mi candidato es Ernesto Talvi. Veamos qué pasa si tomáramos a los 4 vecinos más cercanos:
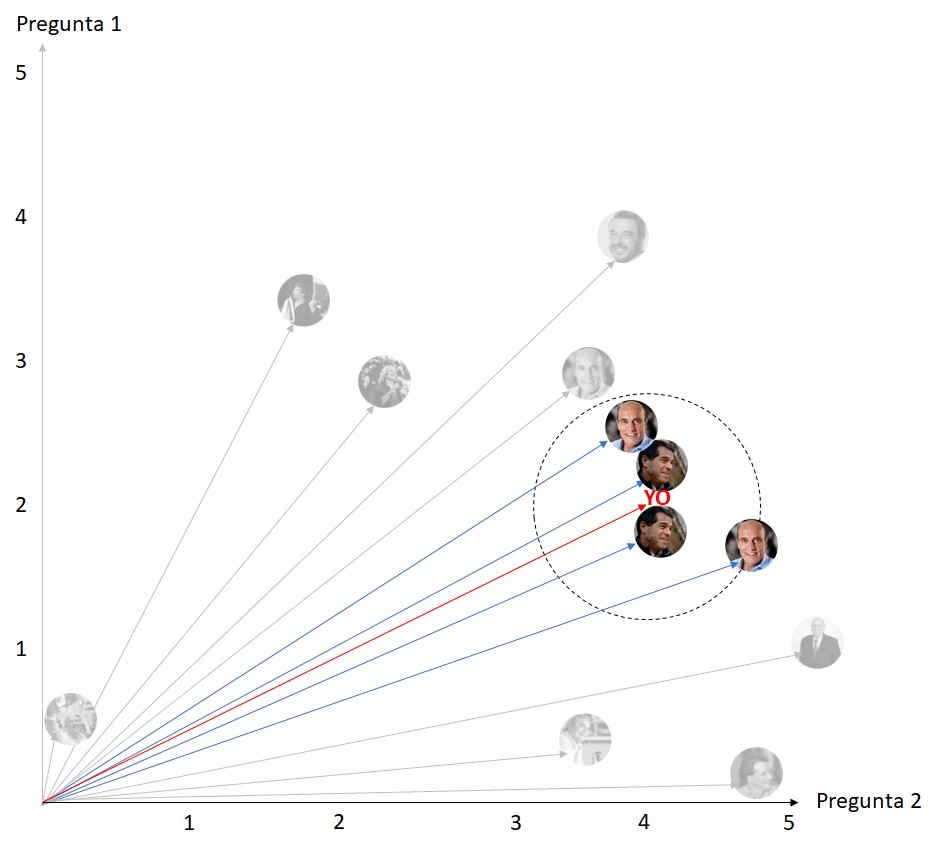
Tomando los 4 vecinos más cercanos vemos que el sistema no podría hacer una recomendación, ya que de los 4 hay dos que están clasificados como Talvi y 2 que están clasificados como Daniel Martínez ¿y si tomáramos 6 vecinos?
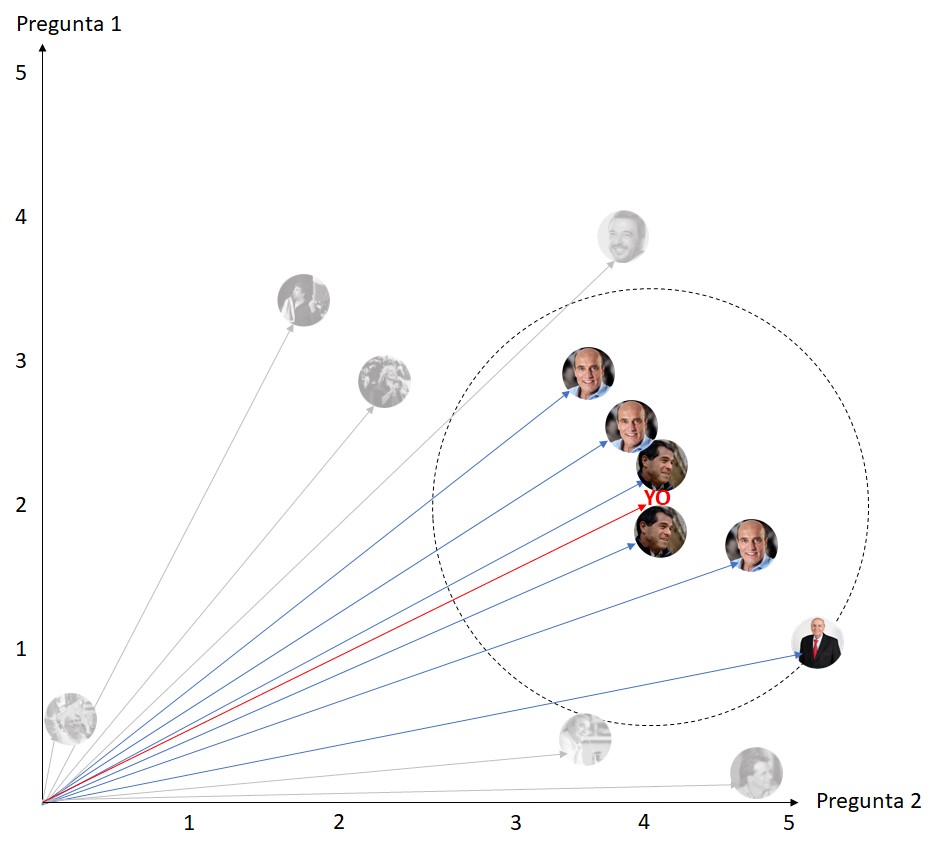
En el caso de tomar 6 vecinos el sistema indicaría que mi candidato sería Daniel Martínez ya que de las 6 respuestas anteriores más cercanas a la mía hay 3 Martínez, 2 Talvis y 1 Julio María Sanguinetti.
En las siguientes partes de este artículo analizaré las respuestas de los usuarios para ver en qué estamos de acuerdo y qué genera más controversia entre los uruguayos y también desarrollaré otros modelos distintos al KNeighborsClassifier.
Consultor en Data Analytics & Information Management