

Interpretabilidad de los modelos de Machine Learning. Segunda parte
Habiendo discutido en el artículo previo la teoría de por qué es deseable la interpretabilidad para entender y poder explotar mejor todo el poder analítico que nos abren los modelos de Machine Learning, ahora enfrentamos el desafío práctico.

¿Cómo interpretar mi modelo de caja negra?
Trabajando a partir de los modelos Generalized Lineal Model (GLM), Gradient Boosted Machine (GBM), Random Forest (RF) y Deep Neural Network (DNN), entrenados con los datos de Job Attrition para predecir la variable categórica desgaste laboral (Attrition).
Se exponen a continuación breves introducciones a 5 de los métodos de interpretación agnósticos al modelo, es decir que pueden ser utilizados independientemente del mismo, del cuadro que vimos al final de la primera parte de esta artículo y su implementación en R en aras de comprender los resultados predichos y su confiabilidad.
• PDP o gráfico de Dependencia Parcial
• ICE o gráfico de Esperanza Condicional individual
• Importancia de Variables
• LIME
• SHAPLEY VALUES
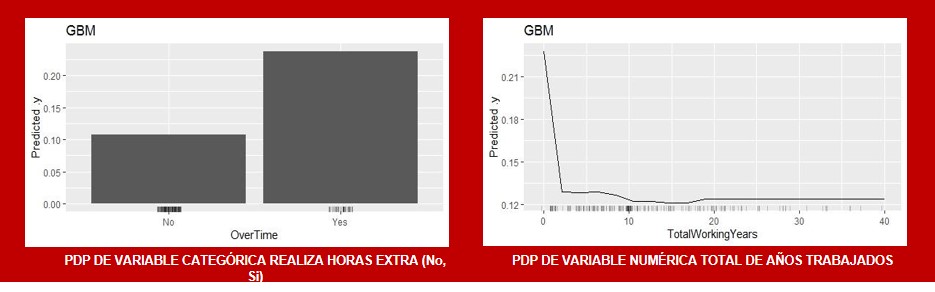
Los PDP muestran el efecto marginal promedio que una o dos características tienen en el resultado predicho por el modelo ml, es decir la dependencia parcial para la variable Xs es la predicción promedio de la estimación del modelo para cada valor que toma esa variable Xs.
El principal problema estadístico de los PDP se da cuando existe correlación entre las variables pues la dependencia marginal calculada para cada valor de Xs sale de la función de predicción conjunta del modelo (lo que el modelo predice para todos los valores de Xs, a través de todos los puntos del modelo del resto de las variables Xc).
El problemas es entonces que al calcular la PDP para todos los valores de Xs puede incluir puntos muy poco probables que ocurran en la realidad o incluso imposible, dado que en el modelo no tienen por qué existir todos los valores de Xs en relación con otra variable correlacionada, por ejemplo salarios altos y nivel de jerarquía bajo.
Fórmula de cómputo
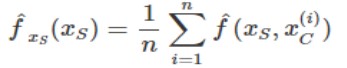
siendo ![]() la función de predicción conjunta del modelo, Xs la variable para la que se calcula el PDP, y Xc el resto de las variables del modelo .
la función de predicción conjunta del modelo, Xs la variable para la que se calcula el PDP, y Xc el resto de las variables del modelo .
VENTAJAS
• Intuitivo es un concepto fácilmente interpretable, la predicción promedio del modelo si forzamos a todos los puntos a asumir el valor de la variable de la que calculamos el PDP.
• Si no existe correlación:
• Representa perfectamente la influencia de la variable en la predicción.
• Tiene interpretación causal entre la variable y las predicciones del modelo (lo que no necesariamente significa que esa causalidad se mantenga en la realidad, eso depende de la corrección del modelo).
DESVENTAJAS
• Esconde la Heterogeneidad entre observaciones al tratarse de un cálculo promedio
• Dos es el máximo numero de Xs ya que al mostrarlo de manera gráfica no tenemos la capacidad de procesar imágenes en 4D.
• No muestra la distribución de Xs -debe ser complementado con histograma o incluir los puntos en el gráfico, para evitar el peligro de sobre interpretar casos de baja frecuencias.
• Asume independencia entre Xs y Xc.
ALTERNATIVAS DE SOFTWARE
• iml, pdp y DALEX en R
• sklearn.inspection.plot_partial_dependence, partial_dependence.PartialDependenceExplainer() en Python
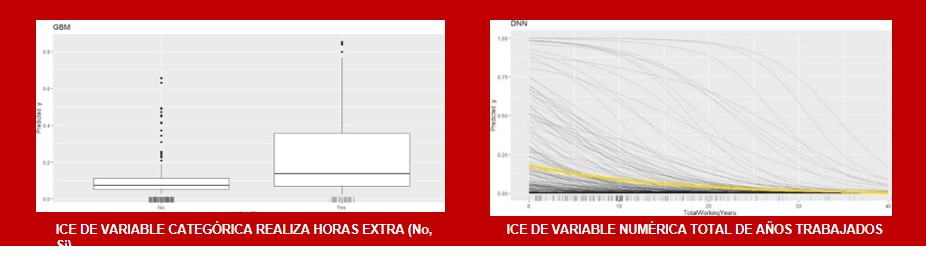
Los ICE muestran una línea, por cada observación, que representa cómo cambia la predicción del modelo ML para esa instancia cuando varían los valores de la característica para la que se calcula.
Miden la dependencia de la predicción en una variable para cada instancia por separado, el promedio de la suma de todas las curvas ICE es la PDP.
Fórmula de cómputo

Siendo Xs la variable para la que se calcula el ICE Xc el resto de las variables del modelo.
VENTAJAS
• Más intuitiva incluso que PDP, una línea representa un caso individual y se puede observar la influencia de la trayectoria de los individuos en las predicciones del modelo.
• Puede representar y hacer notar comportamientos heterogéneos entre observaciones.
DESVENTAJAS
• Solo puede mostrar una variable significativamente (de lo contrario pierde interpretabilidad).
• Si existe correlación entre Xs y el resto de las variables del modelo algunos de los puntos de las líneas graficadas pueden ser inválidos (ficticios).
• El gráfico puede estar sobre cargado de líneas dificultando su interpretación, la solución a este problema podría ser computar las ICE en una muestra de los datos o añadir transparencia al gráfico.
ALTERNATIVAS DE SOFTWARE
• iml, ICEbox y pdp en R
• pycebox en Python
Importancia de variables

Es el aumento en el error de predicción del modelo después de permutar los valores de la variable, rompiendo así la asociación entre la variable y su verdadero resultado.
Los dos casos de cómputo que pueden ser a predecir de interés:
• datos de entrenamiento: cuánto el modelo se apoya en cada variable para hacer predicciones.
• Datos de evaluación: cuánto las características contribuyen a la performance del modelo predictivo.
Forma de cómputo
1. Computar MSE para el modelo original
2. Para cada variable i en {1,…,p}
2.1 Randomizar sus valores (para ello los autores sugieren partir el data set en dos y cambiar los valores de la variable j de cada mitad en lugar de permutarla)
2.2 Aplicar el modelo ML
2.3 Estimar MSE para ese modelo
2.4 Computar la importancia de la variable i como (MSE permutado(paso 2.3)/MSE original(paso 1))
3. Ordenar las variables en orden descendente de importancia.
VENTAJAS
• Interpretación global, resumida y fácil: la importancia de la variable es el aumento del error del modelo cuando la información de esa variable es destruida.
• Recoge también los efectos de todas las interacciones con el resto de las variables, pues las permutaciones destruyen también los efectos de las interacciones, por lo que la importancia de variables toma en cuenta los efectos directos y los de interacción.
• No requiere reentrenar el modelo, otros métodos sugieren comparar los resultados del modelo con y sin la variable de interés.
DESVENTAJAS
• El cálculo incluye estimar distribuciones marginales, con cierta varianza, los resultados pueden ser inestables si no tenemos los suficientes datos.
• Calcula el efecto en la performance del modelo, no los cambios en los valores predichos (no mide robustez).
• Es necesario conocer el verdadero resultado de la variable dependiente a predecir (no se puede usar en modelos de clustering).
• SI EXISTE CORRELACIÓN
• puede incluir puntos irrealistas.
• agregar una variable correlacionada puede hacer decrecer la importancia de la variable asociada.
ALTERNATIVAS DE SOFTWARE
• iml y DALEX en R
• eli5.sklearn.PermutationImportance() en Python
LIME o explicación agnóstica al Modelo de la Interpretabilidad Local
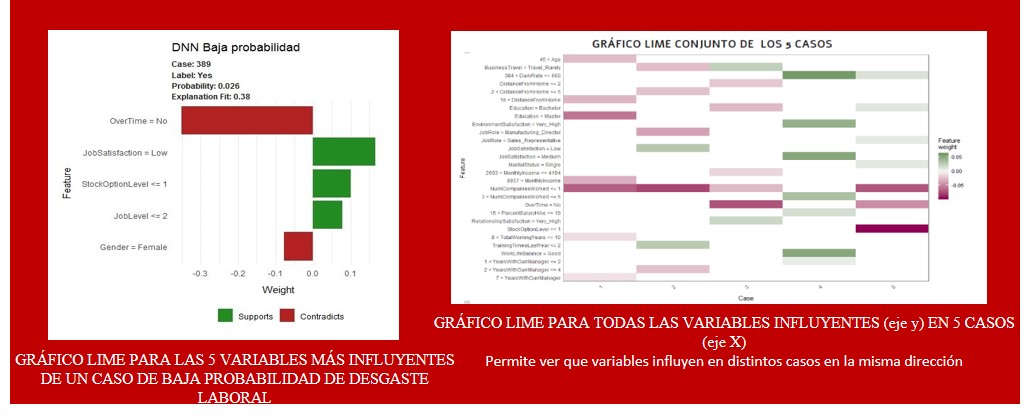
El supuesto detrás de LIME es que cualquier modelo complejo es lineal a escala local, por lo que dos observaciones muy similares se comportan de manera predecible incluso cuando son parte de un modelo ML complejo.
Esto haría posible entrenar un modelo lineal simple alrededor de una sola observación (permutando los datos originales para obtener muestras con observaciones similares) que imite como el modelo caja negra se comporta en ese punto.
El método LIME tiene muchas decisiones libradas al criterio del usuario y como tal hay mucho espacio para optimizar las explicaciones. Los factores que influencian la calidad de las explicaciones son:
• Cómo se crean las permutaciones.
• Cómo se calcula el score de similitud entre las perturbaciones y la observación original.
• Cuántas y como son seleccionadas las variables dependientes del modelo local.
• El tipo de modelo lineal interpretable.
Forma de cómputo
1. Seleccionar la instancia o muestra de interés a la que calcularle su explicación local.
2. Por cada observación x seleccionada permutarla n veces para crear un nuevo data set con datos del entorno de x.
3. Calcular la distancia de todas las permutaciones a la observación original y convertir esa distancia en un score de similitud con el que ponderar la importancia de cada instancia de la muestra.
4. Seleccionar las m variables que mejor describen el resultado del modelo complejo con los datos permutados a incluir en el modelo interpretable.
5. Correr un modelo interpretable con el nuevo data set permutado, explicando el resultado del modelo ML complejo con las m variables seleccionadas en el punto anterior y las observaciones ponderadas según su similitud a la observación original x.
6. Extraer el peso de las variables del modelo simple y usarlo como interpretación a nivel local del comportamiento del modelo ML complejo para casos similares a x.
VENTAJAS
• El uso de un modelo local interpretable permite trabajar con cualquier modelo ML e incluso cambiarlo sin que afecte la herramienta de interpretación.
• Las explicaciones del LIME son comparables, amigables al humano y presentadas de manera visual fácilmente a los usuarios.
• El método LIME es de los pocos interpretativos que funciona para datos en tabla, texto e imágenes.
• La medida de fidelidad (R cuadrado) muestra que tan bien el modelo aproxima las predicciones del modelo de caja negra en el vecindario de una instancia de datos de interés.
DESVENTAJAS
• La correcta definición del vecindario del parámetro de kernel sigue siendo un problema sin consenso al usar el método LIME para datos de tabla. Para cada aplicación hay que probar distintos seteos del mismo y definir cuál es la óptima.
• El principal problema del LIME es la inestabilidad de sus explicaciones, en el artículo los autores mostraron que explicaciones de dos puntos muy cercanos variaban mucho en un contexto de simulación. Lo cual hace difícil confiar en los resultados, es una herramienta a usar con mucho criterio.
ALTERNATIVAS DE SOFTWARE
• Lime o iml en R
• lime.lime(), lime.lime_tabular() en Python
SHAPLEY VALUES
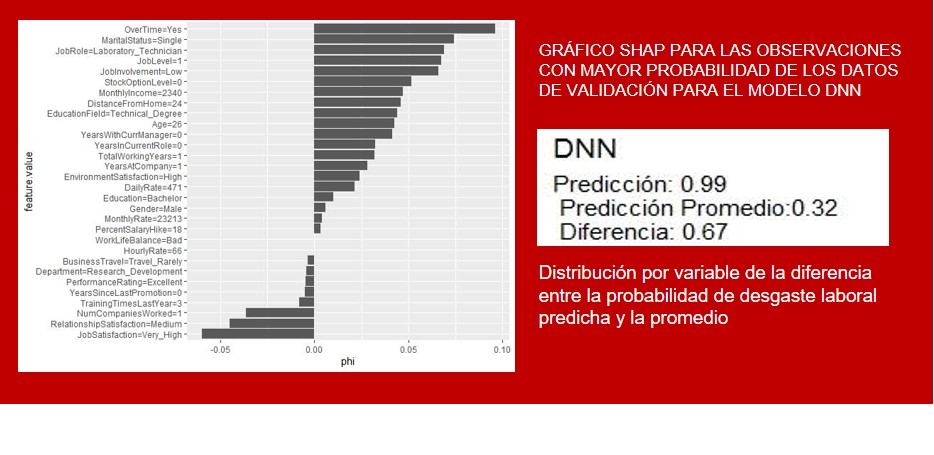
El valor Shapley (ϕ) es un método de cálculo de importancia de variables de un modelo ML complejo que tiene en cuenta el efecto de las interacciones entre variables
La idea es computar la precisión del modelo ML en todas las combinaciones posibles de características que no incluyen X para después agregarles X y observar los cambios en la precisión del modelo, la suma de todos los efectos captados es el SHAP de X
El estimador SHAP busca mostrar la distribución justa de la importancia de las variables. Para ello cumple las siguientes propiedades:
• Eficiencia: captura correctamente el valor de la predicción original.
• Simetría: si dos variables contribuyen igual en todas las coaliciones del modelo, su efecto SHAP es idéntico.
• Dummy: el SHAP de una característica que no altera el valor de la predicción en ninguna coalición es nulo.
• Monotonicidad: si una variable aumenta más la predicción en un modelo que en otro para todas las situaciones, su efecto es mayor en el primer modelo.
Forma de cómputo
1. Sacar instancia random z de la matriz de datos X.
2. Elegir una permutación random o de los valores de la variable.
3. Ordenar instancia x: Xo=(x(1),…,x(j),…,x(p)).
4. Ordenar instancia z: Zo=(z(1),…,z(j),…,z(p)).
5. Construir dos nuevas instancias.
5.1 X+j=(x(1),…,x(j−1),x(j),z(j+1),…,z(p)).
5.2 X−j=(x(1),…,x(j−1),z(j),z(j+1),…,z(p)) .
6. Computar la contribución 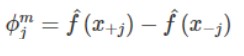 marginal
marginal
7. Computar valor Shapley como el 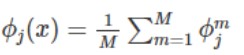
promedio
VENTAJAS
• Cumplir los axiomas de Eficiencia, Simetría, Dummy y Monotonicidad le dan un fundamento estadístico razonable.
• La diferencia entre la predicción y la predicción promedio esta justamente distribuida entre las variables (cumple propiedad de Eficiencia que LIME no garantiza).
• Permite explicaciones a varios niveles, para el total de los datos, una muestra o incluso para una única observación (en contraste con LIME que es solo local).
DESVENTAJAS
• Las explicaciones con valores Shapley siempre usan todas las variables del modelo, son exhaustivas, si prefieren explicaciones selectivas es recomendable usar LIME.
• Shapley devuelve valores de importancia de las variables pero no es un modelo de predicción, no puedo inferir nada ante cambios en el modelo.
• Si existe correlación entre las variables los valores Shapley pueden incluir puntos poco realistas en los datos (usa distribución marginal para imputar puntos faltantes).
• Requiere mucho tiempo de cómputo, el estimador muestrea las coaliciones y limita el número de iteraciones M (lo cual aumenta la varianza del SHAP).
ALTERNATIVAS DE SOFTWARE
• iml en R
• shap.force_plot() en Python

¿Qué técnica debo usar para explicar mi modelo de ML?
Si sospechamos que existe correlación entre las variables del modelo, es recomendable implementar más de un método para aumentar la consistencia y fidelidad de nuestra explicación.
Lo principal para tener en cuenta es para qué o quién estoy generando la explicación y en base se pueden tener en cuenta las siguientes pautas:
• Método local vs global
¿Es necesario entender la lógica completa detrás del modelo o sólo te interesa la razón detrás de una decisión específica?
• Grado de complejidad y exhaustividad
¿Cuál es el cronograma de trabajo? Si el usuario necesita tomar una decisión rápida podría ser preferible tener una explicación simple (LIME, PDP). Si el tiempo no es un problema es recomendable generar una explicación más compleja y exhaustiva.
¿Cuál es el nivel de conocimiento del usuario del modelo ML? Expertos en el tema probablemente prefieran una explicación más sofisticada mientras que otros usuarios pueden favorecer una más simple de entender y recordar
Por más información en el tema recomiendo el libro que me sirvió de guía para armar este post: «Interpretable machine learning. A Guide for Making Black Box Models Explainable» (2019) de Christopher Molnar.
Consultora unidad Data & Analytics