

Interpretabilidad de los modelos de Machine Learning. Primera parte
No entiendes realmente algo a menos que seas capaz de explicárselo a tu abuela.
(Atribuida a Einstein, no hay evidencia concreta)La interpretabilidad es el grado al que un humano puede entender la causa de una decisión.
(Friedman, Jerome H. “Greedy function approximation: A gradient boosting machine.” Annals of statistics. 2001)
Al iniciarnos en el análisis de datos con métodos de Machine Learning (ML) comenzamos a trabajar a través de modelos o algoritmos que permiten aprender automáticamente patrones en los datos y luego usarlos para hacer predicciones u otro tipo de decisiones bajo incertidumbre con nuestros datos futuros.

¿Pero por qué usamos aprendizaje profundo?
Los métodos de análisis de datos clásicos que ayudan a tomar decisiones sobre el futuro, pertenecen al campo de la inferencia estadística. El punto de partida es la elección de un modelo, que supone cierta forma de conducta de los datos cuyos parámetros son que hay que averiguar para aproximar la conducta real de nuestros datos.
Es justamente en este punto donde entra al juego la parte automática del aprendizaje en los modelos de Aprendizaje Automático (o Machine Learning, o ML) y Aprendizaje Profundo (o Deep Learning, o DL), pues con ellos no es necesario hacer supuestos de los patrones existentes en nuestros datos, sino que utilizamos el poder de cómputo de los modelos que tenemos a disposición para que los aproximen por nosotros, descubriendo relaciones que pueden ser desconocidas e invisibles al ojo humano.

¿Quién realiza el análisis de datos?
Automatizar el aprendizaje no significa automatizar toda la tarea analítica, si bien no realizamos supuestos de distribución sigue siendo necesario para el investigador conocer sus datos para poder decidir cuál es la mejor forma que el modelo aprenda.
A su vez, una segunda parte de esta tarea es la elección del modelo de Machine Learning más idóneo para la tarea que necesitamos llevar a cabo y la arquitectura de nuestros datos.
Entonces, el siguiente problema a resolver es cómo elegir el mejor modelo de Machine Learning. En esta tarea es común la aproximación en base a la performance, es decir elegimos el modelo que mejor aproxime a nuestros datos, y en este sentido, los primeros candidatos suelen ser modelos complejos de baja o casi nula interpretabilidad, también llamados por este motivo modelos de caja negra.

¿Qué es la interpretabilidad de los modelos de Machine Learning?
La interpretabilidad de un modelo es el grado al que un humano puede predecir consistentemente los resultados del mismo.
Kim, Been, Rajiv Khanna, and Oluwasanmi O. Koyejo. “Examples are not enough, learn to criticize! Criticism for interpretability.” Advances in Neural Information Processing Systems (2016)
Entender que estamos haciendo es un paso clave para poder mejorarlo, en ML a medida que el campo se fue alejando de los algoritmos clásicos de inferencia estadística como regresiones lineales a modelos más complejos como las redes neuronales se comenzó a hablar de modelos de caja negra.
Esto se refiere al hecho que como científicos podíamos conocer los datos de lo que aprendía para realizar la predicción del futuro (entrada), las predicciones realizadas (salida) y su corrección (performance) pero lo que aprende el modelo de los datos era para nosotros una caja negra, algo que no podíamos interpretar.
Por más que si supiéramos cómo lo aprendía o su funcionamiento, somos incapaces de procesar en nuestra mente lo que el modelo hace adentro de esa caja, simplemente siguiendo los pasos del algoritmo.
Por ello surge la necesidad de diseñar mecanismos que nos permitan entender estos modelos, entrar a esa caja negra para poder comprender cómo el modelo obtiene buenos resultados. Es justamente a esto a lo que nos referimos al hablar de interpretabilidad de modelos de ML.

¿Por qué estudiar la interpretabilidad de los modelos de Machine Learning?
Algunos de los motivos por los que es conveniente explorar y aumentar la interpretabilidad de los modelos de Machine Learning (ML) son:
- Como medida de seguridad y testeo (entender el funcionamiento del modelo puede ayudar a prevenir o anticipar potenciales causas de fallo de este).
- Es una herramienta de detección y debugging de bias, para evitar que el modelo discrimine en base a ciertas características demográficas que lo harían socialmente inaceptable.
- Para mejorar la probabilidad de aceptación social, conocer una aproximación a la explicación de los resultados del modelo hace más propensos a los usuarios humanos a aceptarlo.
- Los modelos de ML solo pueden ser perfeccionados y auditados cuando podemos entender sus resultados y funcionamiento.
El principal objetivo del estudio de la interpretabilidad de los modelos de Machine Learning es conseguir producir una buena explicación de los resultados del modelo.
¿Cuáles son las características de una buena explicación?
Cuando hablamos de poder explicar el modelo tenemos que tener en cuenta para qué generamos esta explicación, distintos usos de un modelo pueden generar distintos requerimientos.
No es lo mismo tratar de comprender un modelo para auditarlo que para presentarlo a un cliente, o considerar un modelo de predicción de scoring donde el usuario final solo recibe una propensión de compra, que un modelo de predicción de enfermedades que puede influir el accionar sobre nuestra salud (es claro que tratando con temas sensibles hay que tener mayor seguridad de lo que informamos).
Para ello, podemos plantear ciertas propiedades deseables en una explicación en las que se pueden fijar umbrales específicos en conjunto con los dueños de los datos para estudiar la interpretabilidad de los modelos de Machine Learning.
Precisión
¿Qué tan bien una explicación predice datos reales desconocidos?
Esta característica es especialmente importante cuando estamos trabajando con un modelo ML predictivo y nuestra meta es explicar el problema real.
Fidelidad
¿Qué tan bien una explicación aproxima los datos del modelo ML predictivo?
Alta fidelidad es lo que garantiza que nuestra explicación sea útil para explicar el modelo, algunos métodos solo la cumplen a nivel local: para un subconjunto de observaciones (LIME) o para puntos individuales (SHAPLEY VALUES).
Estabilidad
Al comparar explicaciones para instancias similares de un modelo fijo, cambios menores en las variables de una observación no deben afectar sustancialmente la explicación sino que la explicación debe ser estable (excepto en casos en donde estos cambios afecten las predicciones del modelo ML real).
Comprensibilidad
¿Qué tan bien los humanos entienden la explicación?
La dificultad de medir y alcanzar esta propiedad es un punto importante en el estudio de la interpretabilidad.
Seguridad o confianza
¿La explicación refleja la confianza de las predicciones del modelo?
Es importante aclarar la veracidad o certeza de los resultados obtenidos por los modelos en su explicación.
Grado de importancia
¿Qué tan bien reflejada está en la explicación la importancia relativa de cada una de los componentes o variables que utiliza?
Esto es importante para poder generar reglas de decisión adecuadas a partir de la explicación o para evaluarlas.
Representatividad
¿Cuántas instancias u observaciones cubre la explicación?

¿Cómo mejorar la interpretabilidad de un modelo de Machine Learning?
Actualmente existen diferentes aproximaciones para interpretar modelos ML. Debajo se presenta un cuadro de resumen con algunas de estas y sus características:
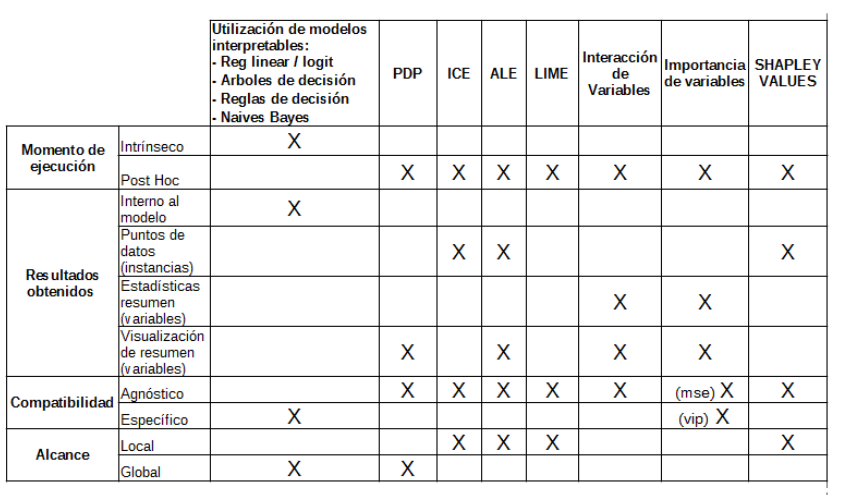
En el próximo artículo presentaré una introducción a la teoría detrás de cinco de estos métodos (PDP, ICE, Importancia de Variables, LIME y SHAPLEY VALUES) y algunas guías a tener en cuenta al momento de usarlos para hacer tus modelos más interpretables.
Consultora unidad Data & Analytics