

Breve llamado de atención sobre los falsos negativos
Nota previa: Se recomienda tener esta música a mano para este artículo: What I Am (Edie Brickell & The New Bohemians, 1988)
Dicen que dicen que un proverbio árabe reza:
El hombre que sabe y sabe lo que sabe, es un sabio, ¡síguelo!. El hombre que no sabe y sabe que no sabe, es simple, ¡enséñale!. El hombre que sabe y no sabe que sabe, está dormido, ¡despiértalo!. El hombre que no sabe y no sabe que no sabe, es un necio, ¡huye de él!.
Seguramente muchos ya lo conozcan. En este artículo los invito a jugar con la idea de un predictor interno, una idea de lo que somos, cómo nos vemos. La intención es explorar con libertad el significado de lo que se predice, y los posibles errores de clasificación; no vamos a entrar en detalles de cuantificación numérica.
Antes de pasar al ejemplo, y a riesgo de pecar de reiteración para los que ya saben, comentemos algunos conceptos:
– Un predictor, es un modelo o algoritmo que nos permite, en base a información con la que contamos (variables de entrada, o features), algún resultado que depende de ellas (variable de salida, o label). Este resultado puede ser una etiqueta de clasificación (label) o un objeto numérico. En el primer caso típicamente hablamos de clasificadores, y en el segundo, de regresores. Un predictor tan obvio como aleatorio es lanzar una moneda, donde el acierto de la respuesta si/no será de 50%.
– Para poder evaluar qué tan bueno es nuestro predictor, necesitamos clasificar los resultados obtenidos, contra la realidad. En el caso más simple, querremos predecir si cierta propiedad se cumple (Positivo) o no (Negativo). Es decir, nuestra variable de salida sería un label binario. Entonces hablamos de:
- Positivos: son los objetos que el predictor afirma que cumplirán la propiedad que queremos predecir.
- Negativos: son los objetos que, según el predictor, no cumplirán la propiedad.
Cuando contrastamos los resultados generados por el predictor contra la realidad hablamos de:
- Verdaderos: los objetos que realmente cumplen la propiedad de interés.
- Falso: los que no la cumplen.
Estamos ahora en condiciones de contrastar lo predicho (Positivo, Negativo) contra la realidad (Verdadero, Falso). Esto es lo que llamamos matriz de confusión, un tópico habitual en aprendizaje máquina.
Volviendo al proverbio árabe -y ahora es buen momento para dar play al tema de Edie Brickel- imaginemos que cada individuo quisiera predecir su sabiduría, reducido al problema binario de «saber o no saber». La etiqueta Positiva, o clase Verdadera, será «sabe». Entonces tenemos esta matriz de confusión:
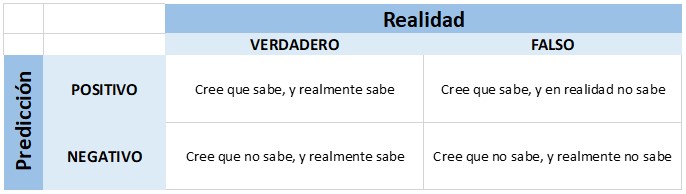
De acuerdo con el proverbio, a cada situación podremos asignarle una interpretación, obteniendo el siguiente cuadro:
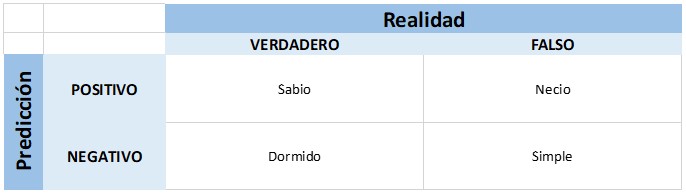
En estadística, el falso positivo también es conocido como falsa alarma, o error tipo I. El falso negativo, error tipo II.
Finalmente, y siguiendo en el proverbio, podemos adjudicar una decisión a cada interpretación:
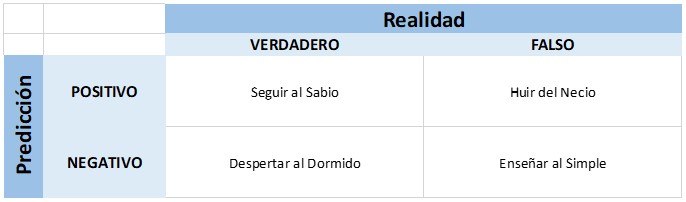
Aquí podemos realizar varias afirmaciones, de acuerdo a las directivas de inferencia y el conjunto de reglas que nos sugiere el texto:
• Los verdaderos positivos son ejemplos a seguir. Son lo mejor que nos puede pasar en términos de precisión (precision) y cobertura (recall).
• Los falsos positivos, además degradar la precisión del predictor, deben ser evitados.
• Los verdaderos negativos no son conscientes de sus potencial, pero están identificados, hay que ayudarlos y así podríamos seguir filosofando. Para eso, los invito a escuchar Filosofía barata y zapatos de goma, de Charly García (1990).
Más allá de fábulas, para saber si un predictor o clasificador funciona bien, las medidas fundamentales serán precisión y cobertura -que podemos intuir viendo la matriz de confusión- o elaboraciones sobre ellas.
En la realidad, esto mapea casos de negocio en términos de ratios o probabilidades de eventos. Algunos ejemplos de estas probabilidades, tomados de casos en que nos ha tocado trabajar son:
- situación de fraude para una transacción determinada;
- que un cliente se convierta en deudor próximamente;
- que un ítem me resulte interesante, considerando mi historia de compras;
- que una sintomatología configure un diagnóstico de enfermedad;
que un cliente deje de serlo; - en una imagen, la seguridad de identificar un objeto de una clase determinada.
Dependerá del caso de negocio cómo ponderar precisión y cobertura, ya que una siempre afecta a la otra. Y también, elegir umbral de seguridad con el que queremos considerar una predicción.
Fernando López Bello @fer_lopezbello
Ingeniero en Computación, PMP
Especialista en Big Data