

¿De qué hablan en Twitter los (posibles) candidatos a presidente de Uruguay? Segunda parte
En el anterior post analicé mediante procesamiento de lenguaje natural los tuits de los candidatos, en esta oportunidad analizaremos sus redes.
Análisis de Redes
Me resultó interesante por otro lado analizar a quiénes siguen los candidatos. Para esto extraje los datos de todas las personas a las que cada uno sigue y dibujé ese grafo:

Es una maraña interesante. Sin embargo podemos analizar las siguientes medidas de centralidad para ver cuáles son los actores más importantes de esta red.
Utilicé 4 medidas específicas: grado, cercanía, intermediación y vector propio (o eigenvector).
• Grado: es la más simple de todas pero a su vez muy representativa, refleja la cantidad de enlaces que tiene cada nodo.
• Cercanía: tiene en cuenta la suma de las distancias más cortas desde un nodo hacia todo el resto de los nodos de la red. Esto se traduce en «cuántos saltos llega una persona a la otra».
• Intermediación: se cuantifica el número de veces que un nodo actúa de puente entre el camino más corto de dos nodos.
• Vector propio: mide la influencia de un nodo en una red. Los puntajes relativos se asignan a nodos en la red en función del concepto de que las conexiones a nodos de puntuación alta contribuyen más a la puntuación del nodo en cuestión que las conexiones iguales a nodos de puntuación baja. Una puntuación alta de vector propio significa que un nodo está conectado a muchos nodos que tienen puntuaciones altas.
Los 50 principales actores de la red son:
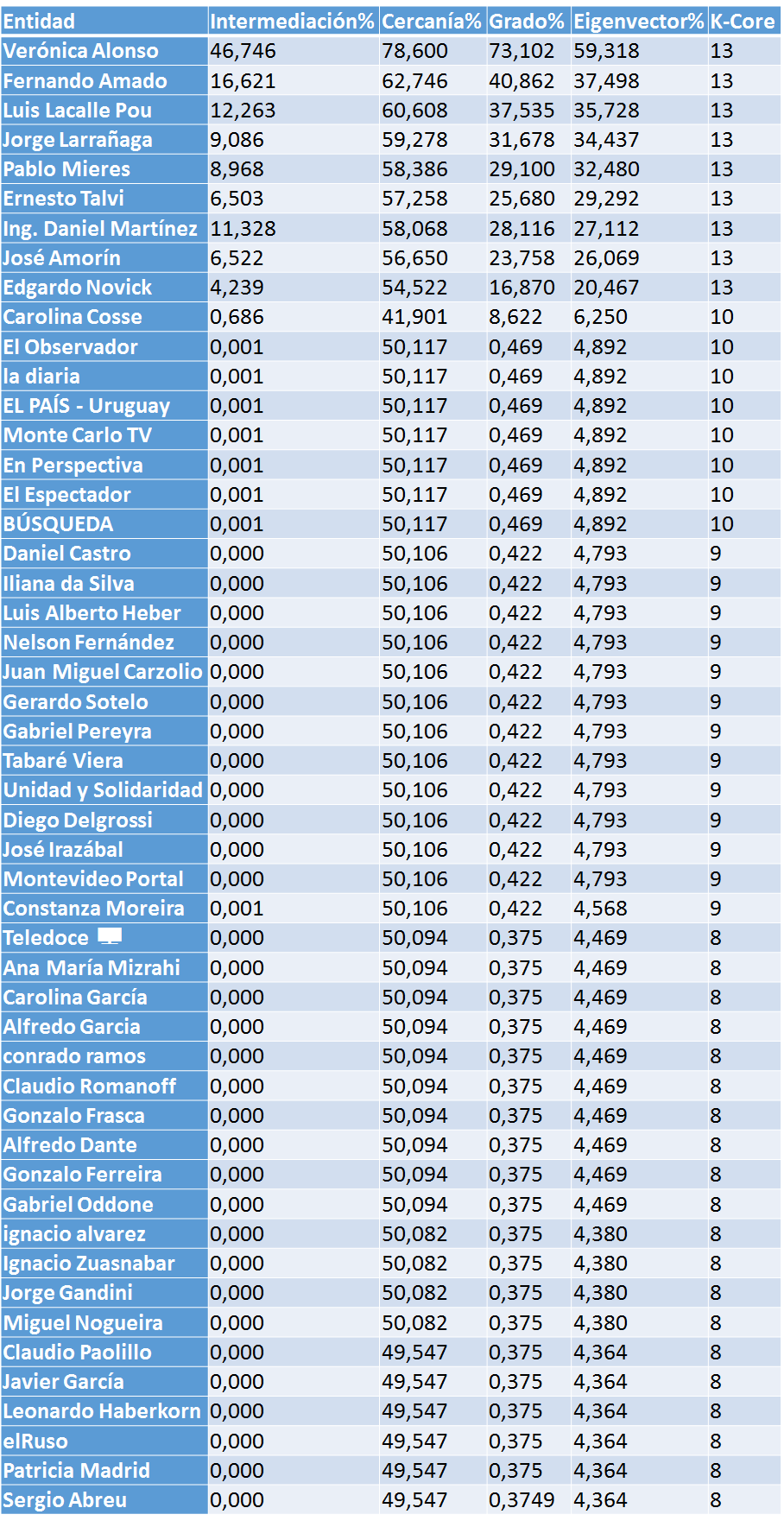
Sígueme y te sigo…
Teniendo en cuenta para el análisis de la red únicamente a los candidatos se puede armar la siguiente matriz de adyacencia:
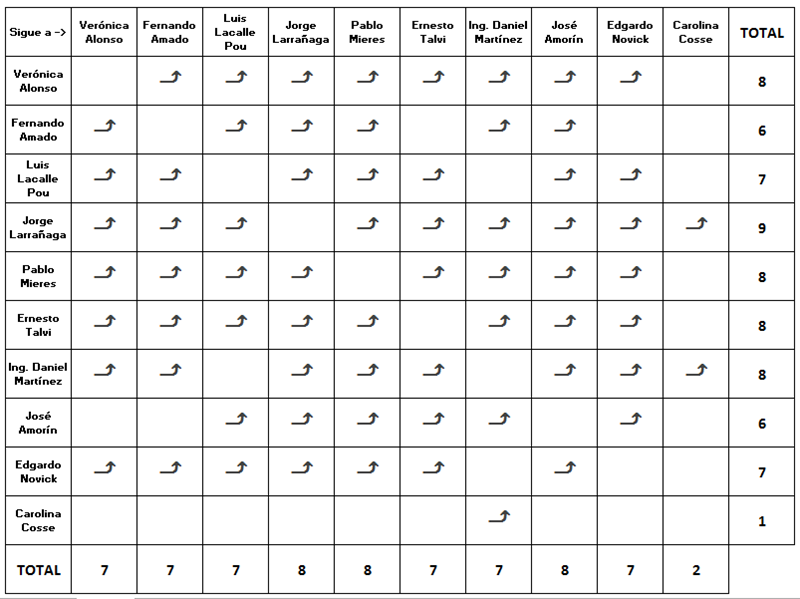
Vemos claramente que el más amoroso es Larrañaga (ya que sigue a todos), la más dura a la hora de demostrar su cariño es Cosse: sigue solamente a uno. Por otro lado los candidatos más populares (más seguidos por sus pares) son Larrañaga, Mieres y Amorín con 8 seguidores cada uno y la más impopular es Cosse.
Teniendo en cuenta la matriz se pueden ver que algunos candidatos se siguen mutuamente, armando un grafo donde los enlaces significan que se siguen mutuamente quedaría así:
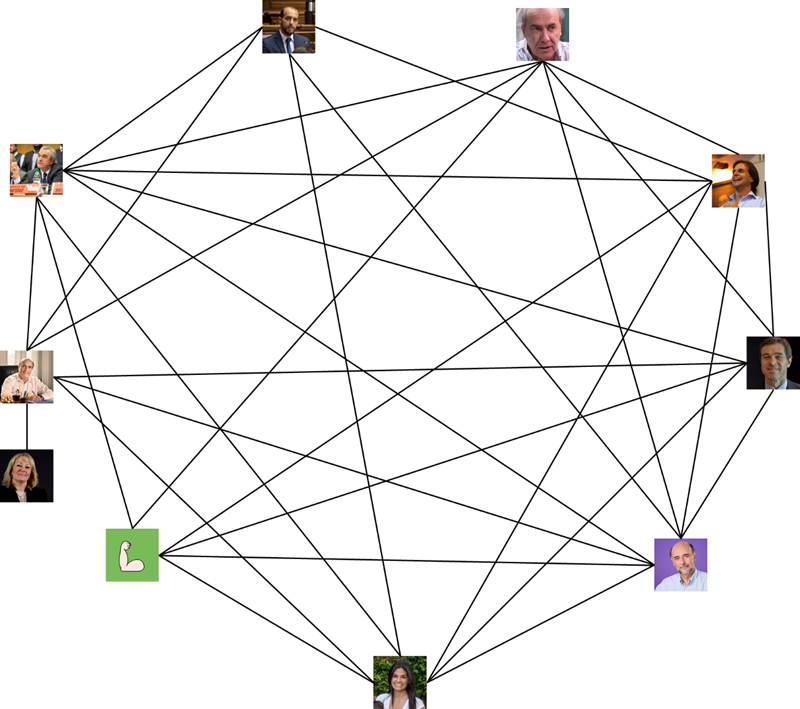
A simple vista (y eso que se dibujó únicamente los vínculos de los candidatos que se siguen mutuamente) vemos que el grafo es muy denso, lo cual considero bastante positivo ya que me parece importante que los candidatos estén al tanto de lo que opinan los otros, al fin y al cabo en el parlamento van a tener que estar en contacto y discutir.
Yendo a los números la densidad de un grafo se halla como la cantidad de lazos que efectivamente existen sobre la cantidad de lazos que podrían existir. En un grafo dirigido con 10 entidades la cantidad posible de vínculos son 90. De los 90 posibles vínculos hay presentes 68 o sea casi un 76% del total. Si no tuviéramos en cuenta a Cosse que es la que está menos conectada el ratio sube a un 90%.
Dime si te gusta él o si te gusto yo
Por otro lado también podríamos armar un grafo dirigido (con enlaces direccionados) dibujando vínculos en los casos que un candidato siga a otro pero el segundo no siga al primero.
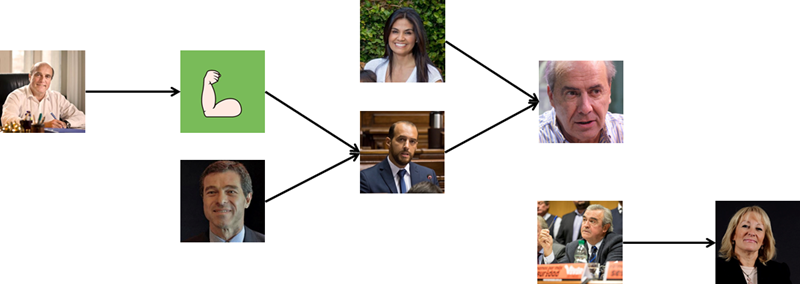
Vemos por ejemplo que Martínez sigue a Novick pero éste no lo sigue. Sin embargo Novick y Talvi siguen a Amado y él no sigue a ninguno de los dos. La política está plagada de amores no correspondidos.
Todo concluye al fin
El análisis de redes sociales o información que hay en Internet en general hace que podamos estar mucho más informados. A esta información se le suele llamar “datos oscuros” y no suelen estar ni cerca tan explotados como los datos que se suelen almacenar en bases de datos internas.
Hay estimaciones que indican que hay empresas que almacenan datos oscuros pero que no llegan a analizar ni siquiera un 1%. Por suerte todo esto está cambiando y hay empresas que están aplicando técnicas de “social media listening” para estar al tanto de lo que se habla sobre ellas en las redes.
Quería agradecerle a Daniela Vázquez por inspirarme a escribir este artículo con su post sobre lo que hablan los parlamentarios en las sesiones de diputados y senadores.
Metodología
El primer paso era obtener los datos.
Para esto intenté usar la API que brinda Twitter pero me encontré con un problema y es que la API estándar está limitada por token de acceso; básicamente te permite hacer una cantidad limitada de requests en una ventana de 15 minutos por lo tanto iba a demorar muchísimo en conseguir toda la información que necesitaba.
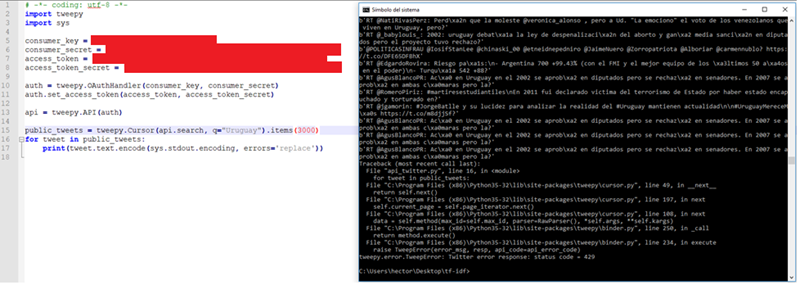
El error code 429 justamente significa que se alcanzó el límite de velocidad impuesto por la API que se está utilizando. Vi que hay APIs más allá de la standard (también gratuita en algún caso) pero que también tiene topes así que decidí ir por otro camino.
Para sortear el obstáculo decidí scrapear la página (scraping significa transformar el contenido no estructurado de un sitio web en datos estructurados, los cuales pueden ser almacenados en una base datos o en una hoja de cálculo) utilizando dataminer. Gracias a esta herramienta logré hacer una «receta» (casi) ideal que me extrae los datos (casi) exactamente como los quiero.
Acá se ve parte de la definición de la receta:
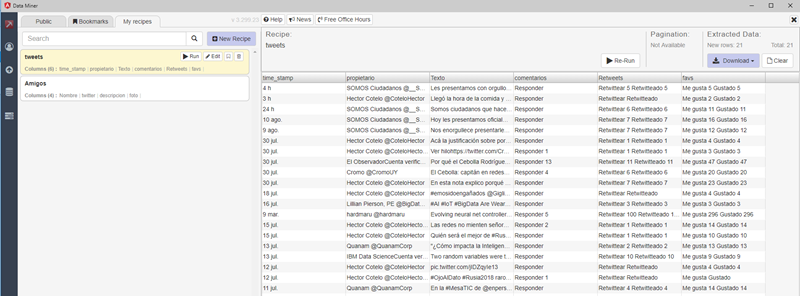
Y acá el resultado:
De esta forma extraje todos los tuits desde el 1°/1/2018 hasta agosto de los siguientes candidatos: Pablo Mieres, José Amorín, Fernando Amado, Verónica Alonso, Edgardo Novick, Luis Lacalle Pou, Carolina Cosse, Daniel Martínez, Larrañaga y Ernesto Talvi.
Luego con Python parseé los textos e implementé todos los cálculos que explico a continuación. Lo que sucedió fue que al compartirlo con algunos conocidos me empezaron a hacer más preguntas por lo que decidí insertar todos los datos en una base de datos ya que una vez allí iba a ser más rápido (para mí) extraer resultados que mediante programación puramente. Además, una vez en la BBDD podía usar una herramienta de Business Analytics (en particular utilicé Cognos) para hacer los gráficos y demás.
Aquí se ve la estructura de las tablas de la BBDD:
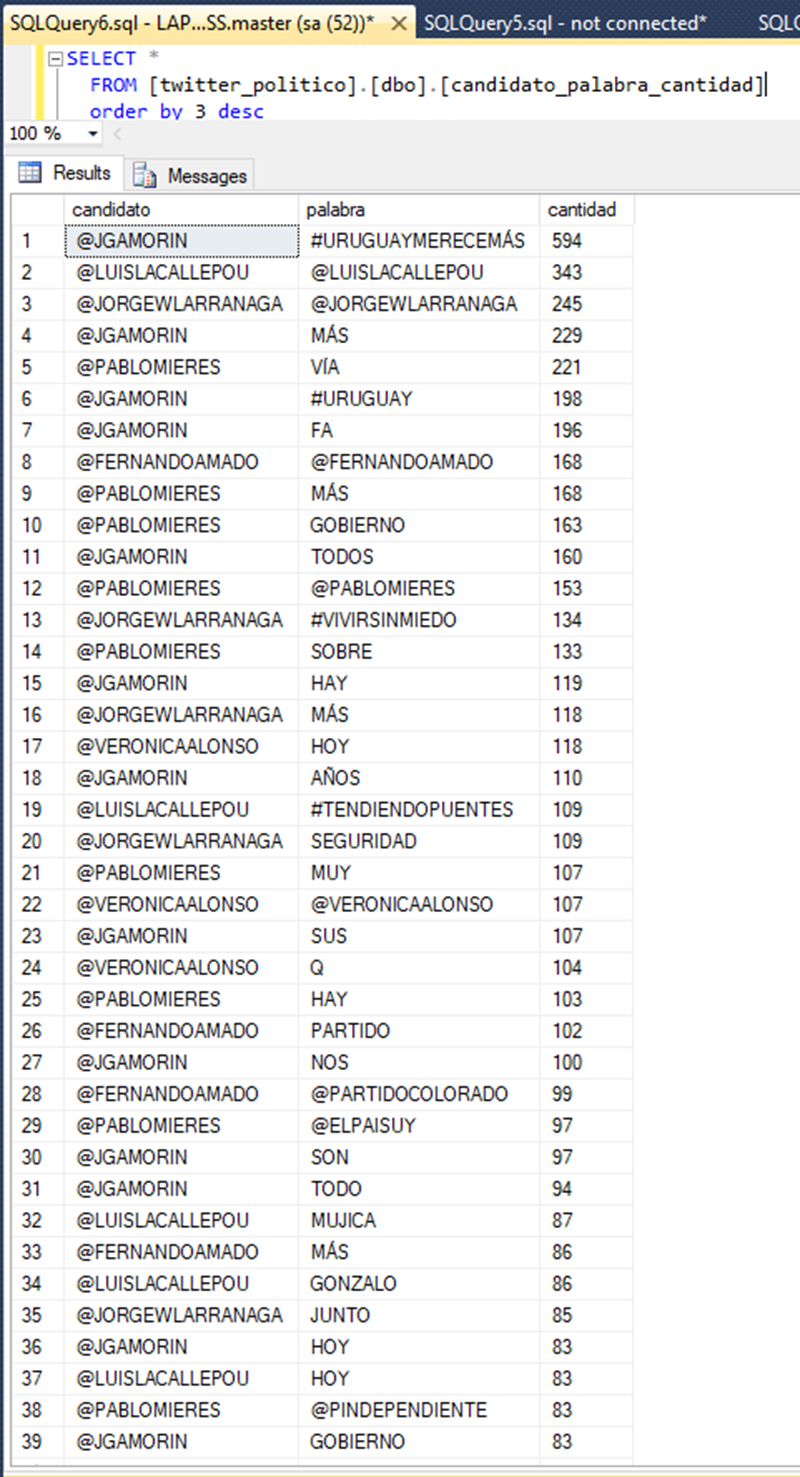
Acá algunos de los datos que hay en una de las tablas:
Y también la pequeña metadata implementada en Cognos para poder hacer los reportes:
Consultor en Data Analytics & Information Management