

MLOps – Parte 1
Con ustedes… MLOps
MLOps tiene que ver con pasar del hito a la continuidad operativa. Aquel proyecto data science tan innovador que brilló dando solución a un problema específico, capaz de responder preguntas desafiantes como predicciones, ahora debe convertirse en una solución evolutiva, capaz de crecer tanto en complejidad como en volumen de datos, controlando responder con calidad, y disponibilidad total.
Desde hace tiempo sabemos que las soluciones que incorporan aprendizaje automático[1], como todo proyecto de ingeniería de software, implican una cantidad de componentes en donde el código propio de machine learning tiene un peso relativo muy acotado. Con esto queremos decir que se trata de un flujo de trabajo amplio (Figura 1), donde hay componentes que van desde la configuración hasta el monitoreo, pasando por la recolección de datos, generación de atributos y una infraestructura de servicio que asegure la disponibilidad del modelo en cuestión.
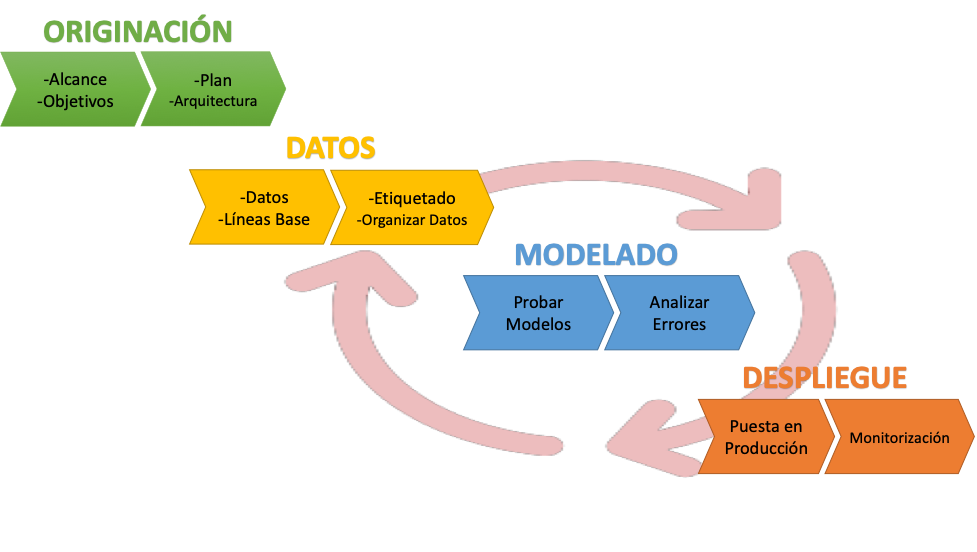
Figura 1 – Etapas en un Proyecto de Aprendizaje Automático
Comenzamos (Originación) por definir un alcance bien delimitado con unos objetivos medibles. Confeccionamos un plan de proyecto que incluirá aspectos como definición de la arquitectura, capacitación del equipo, y el cronograma para las etapas subsiguientes.
La información (etapa Datos) es central a este tipo de proyectos, y es donde destinaremos la mayor cuota de esfuerzo: probablemente bastante más de la mitad de la dedicación, de todo el proyecto. Tener los datos es el punto de partida para generar los insumos que todo modelo necesitará. Los datos deben ser curados, perfilados, librados de errores para así poder definir los atributos sobre los que edificar nuestros algoritmos de data science o machine learning. Empezamos a hablar en este momento de lineas base, primero a nivel del perfil de los datos, y luego a nivel de modelos. Necesitamos además clasificarlos, asignarles una etiqueta y organizarlos en nuestro repositorio (Feature Store) típicamente un data lake.
Una vez definidos los atributos con los que trabajaremos, el Modelado implicará proponer y probar diferentes algoritmos, ideados por los data scientist del equipo –y por qué no, con apoyo de AutoML- buscando la mejor performance de los resultados, siempre teniendo en cuenta ecuanimidad y privacidad.
Los modelos deberán ser disponibilizados (Despliegue) considerando las condiciones operacionales de nuestro caso –por ejemplo, ser capaz de correr en un dispositivo móvil-, asegurando responder siempre, y que la respuesta sea de calidad.
Este ciclo Datos – Modelado – Despliegue seguirá realizándose a lo largo de la vida de nuestra solución, contemplando la capacidad de ajuste que la dinámica de la realidad exija.
Conceptos
MLOps tiene su antecedente directo en DevOps y DataOps, por lo que vale la pena detenernos un momento en ellas:
- DevOps (development operations) surge como respuesta a la progresiva complejización del ciclo de desarrollo de software, donde fue ganando preponderancia el esfuerzo destinado a operaciones de IT. Se trata entonces de acortar los tiempos propios del ciclo de implementación, asegurando integración continua sin perder calidad.
- La integración continua tiene que ver con unir el trabajo de todos los desarrolladores en una troncal que se pueda desplegar varias veces por día
- Entrega continua refiere a la producción de software en ciclos cortos, asegurando que se pueda testear de manera confiable en cualquier momento y en forma automática
- DataOps (data operations) es una metodología orientada a procesos utilizada por los equipos de analítica de datos para mejorar la calidad y reducir el tiempo de ciclo de analítica de datos
- MLOps, en línea con las anteriores definiciones, es el conjunto de prácticas que apunta a desplegar y mantener modelos de aprendizaje automático en producción de manera confiable y eficiente
Una solución de MLOps debe funcionar en un espacio de condiciones operacionales aceptables. Debemos controlar que se tenga el nivel de performance adecuado bajo unos parámetros operativos adecuados, y para esto tenemos:
- Métricas propias del aprendizaje automático, como precisión, exactitud, balance F1 y muchas más derivadas de ellas
- Métricas de ingeniería de software como la latencia y el rendimiento. La latencia es el tiempo transcurrido entre que el usuario solicita un resultado y lo recibe. El rendimiento es el tiempo requerido para completar un proceso.
76% of IT leaders say they continue to struggle to strike the right balance between business innovation and operational excellence.
Source: IDG
Aprendizaje Automático Centrado en Datos
En los últimos tiempos estamos asistiendo a una redefinición del sistema de inteligencia artificial. En esta concepción renovada visualizamos que este tipo de sistemas se componen de 2 grandes pilares: el código y los datos, por igual. Si nuestro foco está en el código, entonces trabajaremos sobre un juego de datos estático probando diferentes modelos, eligiendo el modelo que más nos convenza, y luego nos abocaremos a ajustar los hiperparámetros del mismo. Si por el contrario damos más énfasis a los datos, como es la tendencia actual, entonces habremos elegido un modelo que dejaremos estático, y trabajaremos en iteraciones sobre los datos logrando un mejor data set con nuevos y mejores atributos cada vez.
¿Por qué este [renovado] énfasis en los datos? Una explicación puede estar en el avance de los métodos de ML con que contamos hoy. La versatilidad de los diferentes algoritmos de ML actualmente disponibles, a lo que debemos sumar las capacidades de entrenamiento automático -tanto para selección de hiperparámetros como para definición de arquitecturas de modelos-, nos permiten en buena medida confiar en que ese algoritmo que buscamos, existe.
Lo que no podemos reemplazar, es precisamente los datos. Aunque esto tampoco es del todo cierto: es posible generar datos artificiales, ya sea componiendo más datos o agregando ruido. Un ejemplo son las GANs (Generative Adversarial Networks), frecuentemente utilizadas para control de calidad industrial. Cabe aclarar que la generación sintética de datos es mucho más asequible para datos no estructurados, que para los que siguen un esquema determinado, generalmente asociado a alguna transacción de un sistema gestión.
El foco en los datos nos obliga a especializarnos en sacar el máximo provecho a la hora de generar atributos: debemos seleccionar los atributos más representativos de nuestro problema, los más ricos como entrada a un modelo. Para hacerlo, echaremos mano de técnicas de selección, con diferente grado de automatización. Así, por ejemplo, eliminaremos aquellos que sean redundantes o dependientes de otros. Existen algoritmos que analizan los atributos disponibles –que fácilmente podrían ser cientos- para quedarnos con el mejor subconjunto.
La ingeniería de atributos tiene por cometido lograr el mejor input para la etapa de modelado. Y va mucho más allá de la selección: implica combinar atributos para generar nuevos, convertirlos en nuevos tipos de datos, inventar representaciones –por ejemplo, embeddings (vectores) de palabras-, o también re-escalar (normalizar).
Tanto los datos, como su esquema descriptivo, pueden degradarse con el tiempo. Aunque más que degradación, sería más justo hablar de sesgo. Dependiendo de la magnitud del cambio histórico en los datos, podremos hablar de deriva de datos, o deriva de concepto.
No menos importante es el perfilado y exploración de los datos. Recordemos el ejemplo del cuarteto de Anscombe, donde podemos apreciar que una métrica estadística no es suficiente para perfilar la información.
Estas tareas de la etapa de Datos donde validamos (tipo y dominio de valores), describimos, depuramos, modificamos dimensionalidad y generamos nuevas representaciones, pueden ser convenientemente organizadas como pipeline en la forma de un grafo dirigido acíclico, donde en cada paso (nodo) vamos realizando en orden esas actividades.
Pipelines para MLOps
El proceso cíclico que comprende MLOps comienza en los datos, pero también presta mucha atención al despliegue de la solución de ML. Pero… ¿cómo llegamos desde los datos, hasta modelo en producción, de una manera ordenada, metódica, gobernable? Ahí es donde luce MLOps como metodología, acompañada de las herramientas que permiten instrumentar estas buenas prácticas.
Un ejemplo muy popular es Tensorflow Extended (TFX), gratuita y de código de abierto, impulsada por Google.
TFX implementa el pipeline de MLOps a través de una colección de componentes orquestados, utilizable y personalizable en Python, que comprende las fases de ingesta, validación, transformación, entrenamiento, y despliegue incluyendo monitorización.
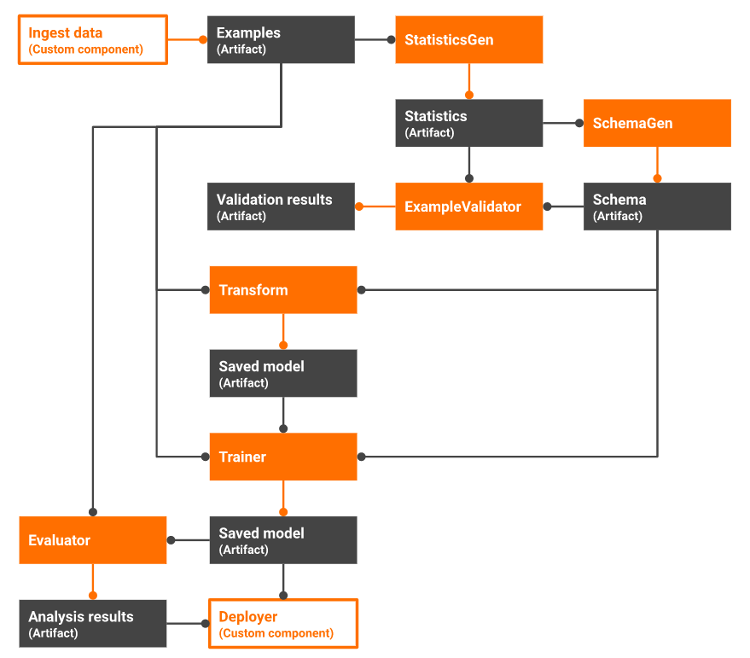
Figura 2 – Pipeline en TensorFlow Extended
https://www.tensorflow.org/tfx/guide/understanding_tfx_pipelines
Esto es todo por ahora, a modo introductorio. Próximamente continuaremos profundizando sobre MLOps.
[1] D. Sculley et al., «Hidden technical debt in machine learning systems», Adv. Neural Inf. Process. Syst., vol. 28, pp. 2503-2511, 2015.