

¿Cuáles son los mejores equipos y pilotos de la Fórmula 1 en la actualidad?
¿Alguna vez pensaron hacer apuestas haciendo análisis de clusters?
Este análisis comenzó con la idea de crear el mejor equipo posible para el Formula 1 fantasy, y así poder ganar la apuesta hecha con mis amigos. Para crear el mejor equipo mi idea fue separar a los pilotos por clusters (grupos), interpretar esos grupos para entender qué criterios utilizó el algoritmo para dividirlos a los pilotos y, con un poco de suerte, saber qué pilotos son los mejores en la presente temporada.
Este análisis comenzó el 04/05/2022, hasta esa fecha se habían disputado 4 fechas de la Fórmula 1. Estas carreras fueron en Bahrein, Arabia Saudita, Australia e Italia, donde se guardaron datos como: nombre, nacionalidad, edad, equipo, puntos piloto, puntos equipo, calificación y carrera de los 4 países donde se disputaron de cada piloto .
Este año están corriendo diez escuderías con dos pilotos por carrera cada uno, pero en las primeras dos carreras el piloto Sebastian Vettel fue diagnosticado con Covid-19, por lo tanto el no disputó el Gran Premio de Bahrein y Arabia Saudita, el piloto sustituto fue Nico Hulkenberg.

Data Cleaning & Feature Engineering
En el dataset original se muestran todas las fechas del campeonato 2022, incluso las que todavía no se disputaron. Por lo tanto procedí a eliminar esas carreras y a hacer un poco más de data cleaning. El dataset original se veía así:
Luego de eliminar algunas columnas con datos vacíos, cambiar datos de tipo object a integer o float, cambiar la columna ‘Team’ por (campeonatos ganados/campeonatos disputados) y agregar columnas como ‘total_DNS’(did not start) y ‘frequency’ (cantidad de carreras en los puntos / cantidad de carreras), el dataset quedó de la siguiente forma:

K-means
Luego de limpiar los datos estábamos listos para realizar los clusters. Para saber en cuantos grupos separar los pilotos realizamos un mecanismo conocido como el método del ‘codo’, lo que este método hace es ayudar a los científicos de datos a seleccionar el número ideal de grupos. Para encontrar el número ideal de divisiones, este modelo prueba con distinta cantidad de clusters y luego calcula cada métrica de error. Cuando termina de probar los distintos clusters, se muestra en una gráfica donde X=cantidad de clusters e Y=distorsión. Al observar la gráfica es fácil de entender porque se le llama método del ‘codo’, donde el codo sería el punto de inflexión en la curva. En este ejercicio, la métrica de error es la distorsión (el eje Y del gráfico), que calcula la suma de las distancias al cuadrado desde cada piloto al centro del cluster asignado. Sin embargo, también se pueden usar otras métricas, por ejemplo el promedio de los coeficientes de Silhouette (que también fue utilizado pero no se muestra en la gráfica).
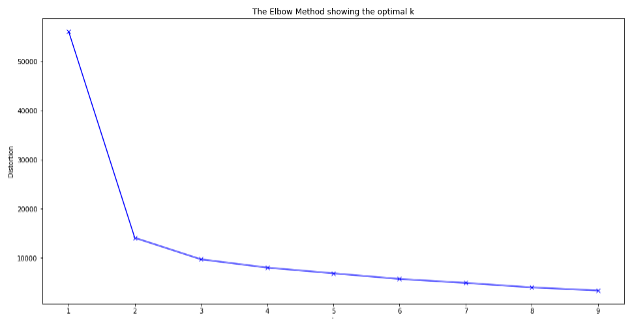
Al aplicar K-means con k=2 al dataset, el algoritmo asigna a cada corredor en el cluster 0 o en el cluster 1. Hasta aquí solo sabemos que hay X corredores en el cluster 0 y Z corredores en el cluster 1, pero no sabemos cómo se diferencian el cluster 0 del 1, es decir, qué es lo que identifica a cada cluster.
Interpretabilidad
Para solucionar este problema, procedí a realizar un Radar Chart, así poder visualizar al mismo tiempo la diferencia de los clusters en las columnas más importantes.
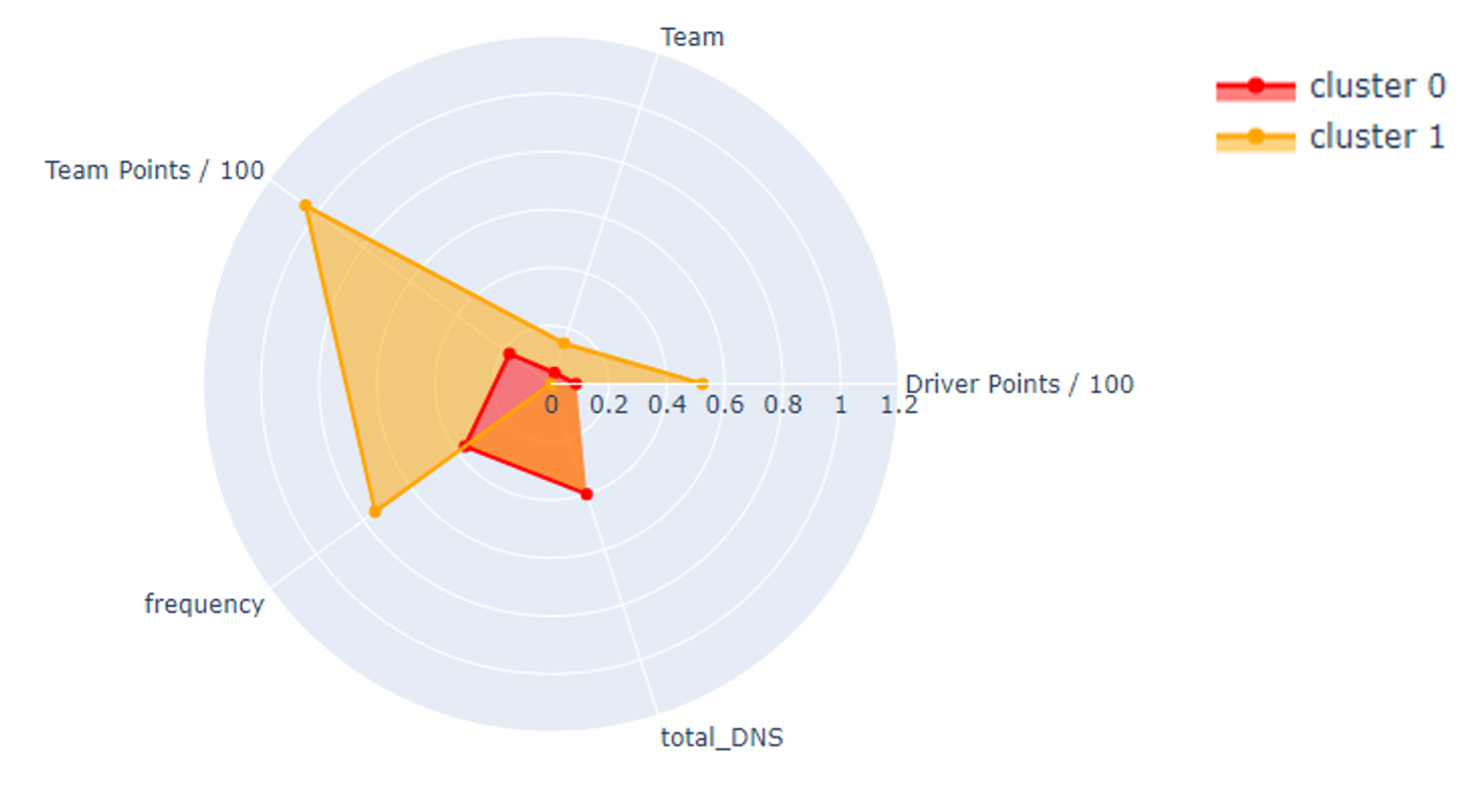
Al observar esta gráfica podemos concluir que en el cluster 1 quedaron los mejores pilotos, estos pilotos son aquellos que tienen más puntos, tanto individuales como del equipo, también son los que están más frecuente en los puntos y un equipo con mayor cantidad de campeonatos. En el único aspecto que le ‘gana’ el cluster 0 es en ‘total_DNS’ que es la cantidad de carreras que los pilotos no iniciaron. Por lo tanto es un dato en el cual te favorece tener lo menos posible.
El aprendizaje automático tiene un gran potencial pero los algoritmos generalmente no explican porqué hacen lo que hacen (en este caso porqué pone a un piloto en un grupo o el otro), lo que es una barrera para la adopción del aprendizaje automático. Por suerte existe todo un área que trata sobre cómo hacer que los modelos de aprendizaje automático y sus decisiones sean interpretables. Algo muy común es intentar determinar la importancia (el poder de clasificación) de las características. En ese sentido e intentando saber cuáles son “las reglas” que utilizó el algoritmo para separar los clusters hice un RandomForestClassifier utilizando el cluster asignado como objetivo a predecir por el clasificador, lo que esto hace es crear muchos árboles de decisión. El primer resultado, luego de interpretarlo, nos dio es un resultado muy fácil y visible a simple vista, este resultado es:

Lo que esto quiere decir es que si los puntos de equipo son mayores a 61.5 van al cluster 1 y de lo contrario al cluster 0. Para dificultar el trabajo decidimos eliminar la columna ‘Team Points’, al hacer esto el resultado cambió y no es tan simple de visualizar. El resultado luego de hacer este cambio es:
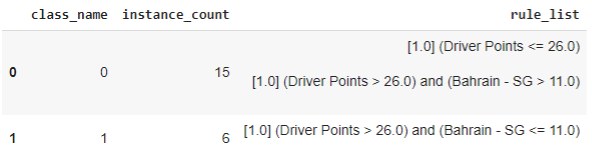
Aquí está la nueva forma de dividir los clusters sin tener a la columna ‘Team Points’, si alguien quiere dividir los clusters a ojo en este caso es más complicado. Los pilotos que se encuentran en el cluster 1 son los que tienen ‘Driver Point’ mayor a 26.0 y la clasificación en Bahrain menor a 11.0. Por otro lado en el cluster 0 quedaron todos los que tienen menos de 26.0 “Driver Points” y todos aquellos que tienen más de 26.0 “Driver Points” pero un valor menor a 11 en la clasificación de Bahrain.
Resultado
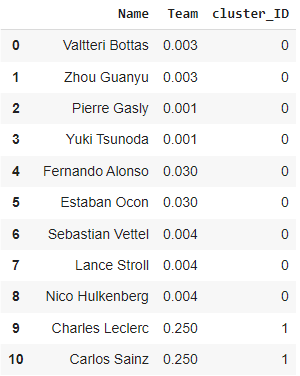
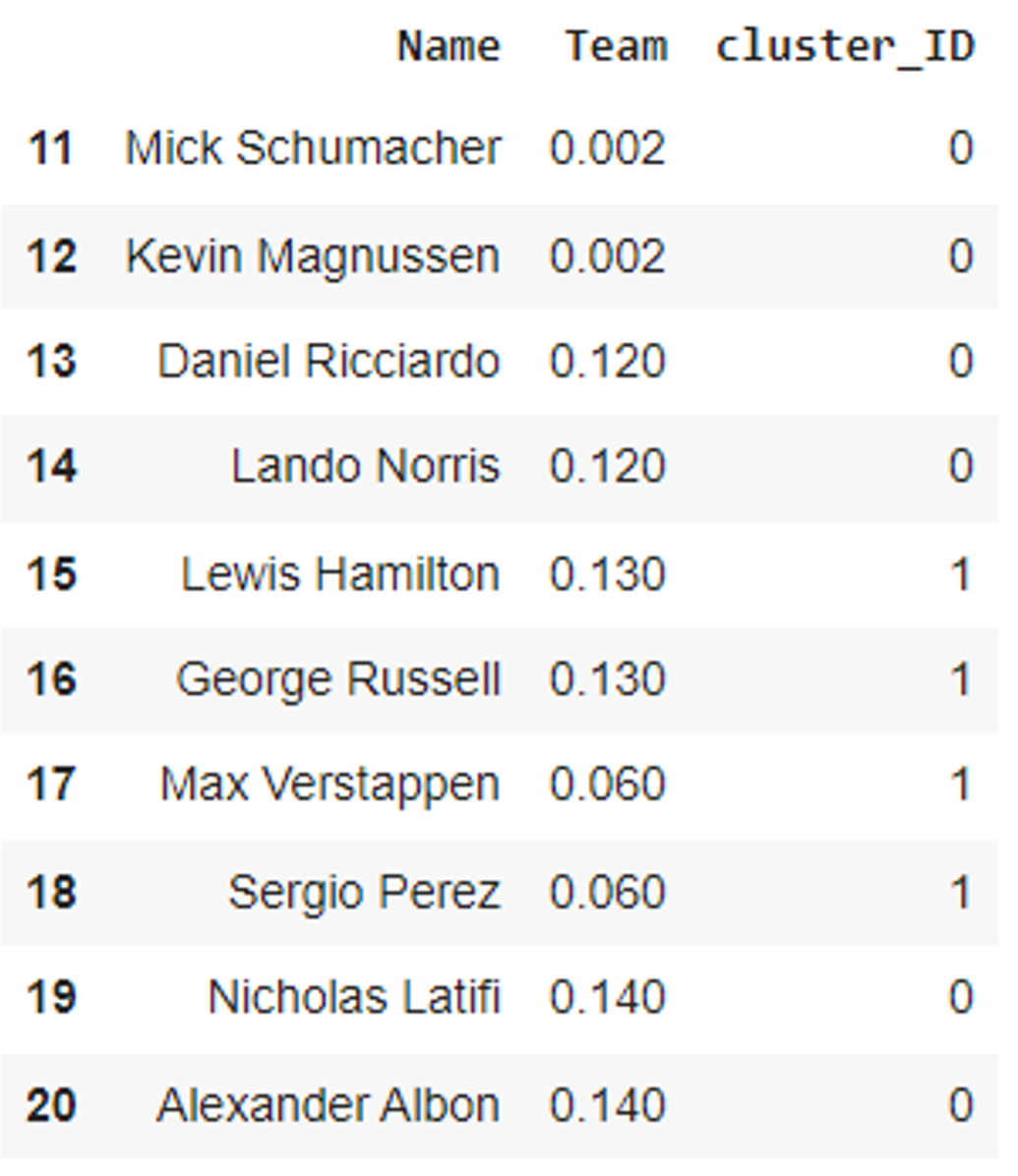
Al observar que piloto quedó en cada cluster pude hacer mi equipo en el Formula 1 Fantasy. Si bien no fui capaz de seleccionar todos los pilotos del cluster 1 ya que tenía un presupuesto para gastar y los corredores del cluster 1 son los que cuestan más, pude seleccionar a tres pilotos que si se encuentran en este cluster y dos pilotos que se encuentran en el cluster 0.
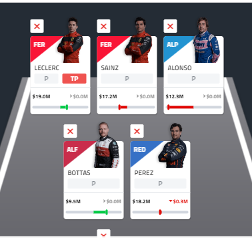 La foto que está a la izquierda es del equipo que selecciones para jugar la apuesta, aquí se puede ver los tres pilotos del cluster 1, estos son: Leclerc, Sainz y Perez. Y los dos pilotos del cluster 0: Alonso y Bottas.
La foto que está a la izquierda es del equipo que selecciones para jugar la apuesta, aquí se puede ver los tres pilotos del cluster 1, estos son: Leclerc, Sainz y Perez. Y los dos pilotos del cluster 0: Alonso y Bottas.
Resultado al cambiar el equipo de Fórmula 1 fantasy
Gracias a la selección de pilotos que hice luego de terminar la investigación pude mejorar mis resultados y acercarme al primer puesto, en caso de terminar en el primer puesto, me llevaré el premio. Si observan bien la imagen debajo, pueden ver como luego del Gran Premio de Miami mis resultados mejoraron mucho, quedando segundo y primero en España y Mónaco respectivamente. La mejora de los resultados es causada por el cambio en el equipo luego de realizar la investigación.
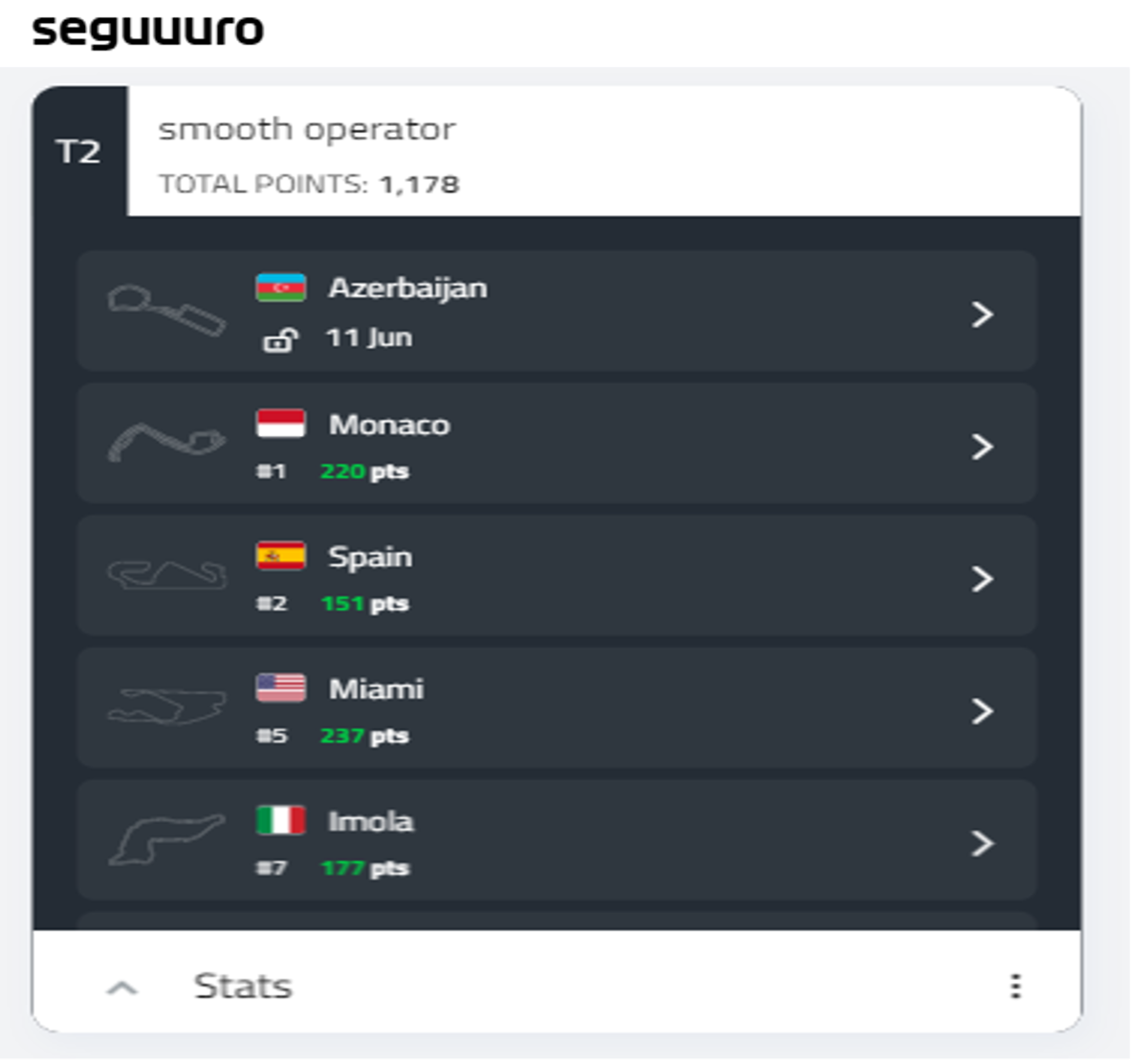
La apuesta hecha con mis amigos termina el 20 de noviembre, en esa fecha se disputa la última carrera del año en Abu Dhabi, por ende se termina la apuesta y se conocerá el ganador de la apuesta.
Conclusión
Como conclusión, si bien no termine primero en las 2 fechas disputadas luego de utilizar la información del análisis para mejorar el equipo, entiendo que la investigación ayudó mucho a mejorar el equipo y por ende los resultados luego de cada fin de semana.
Bibliografia
(2022). Rpctv.com. https://media.rpctv.com/p/a04dfbff0df5b7f3a4baddbd2967e91a/adjuntos/314/imagenes/017/860/0017860548/855×0/smart/000_32bh72jjpg.jpg
{kind=link}