

¿Cómo hacen los Bancos para adaptarse a un cliente cada vez más dinámico?
El mercado cambió, ahora son los Bancos los que tienen que atraer a los clientes ofreciéndoles buenos productos. Los buenos productos, van atados a la calidad y para que esto se cumpla, hay ciertas variables que deben analizarse.
Un claro ejemplo, es el ingreso de las personas, ya que es la manera de saber qué capacidad de repago se tiene y que tipo de productos se les puede ofrecer.
Es aquí, donde entra el concepto de inteligencia artificial basado en el modelo de estimación de ingresos, siendo está una de las herramientas más eficaces para solucionar el problema o para ayudar a los bancos a crear nuevos e innovadores servicios.
El camino hacia ofertas personalizadas
 Las Instituciones financieras están evolucionando su tradicional comportamiento reactivo ante posibles clientes a una conducta mucho más proactiva que consiga adaptar su cartera de productos y servicios a las necesidades particulares de cada persona.
Las Instituciones financieras están evolucionando su tradicional comportamiento reactivo ante posibles clientes a una conducta mucho más proactiva que consiga adaptar su cartera de productos y servicios a las necesidades particulares de cada persona.
Una de las principales actividades bancarias es la financiación a clientes, y uno de los elementos clave en el proceso de admisión de crédito es la determinación de la capacidad de pago de los clientes.
La determinación de capacidad de pago tradicionalmente es un proceso de validación soportado en la documentación que pueda aportar el solicitante de crédito, sin embargo, las nuevas tendencias obligan a las Instituciones a ser capaces de agilizar los procesos de concesión e incluso ser capaces de dar un valor añadido al cliente el no tener que aportar tanta documentación.
Ante esta nueva realidad se hace imprescindible adoptar nuevas técnicas que permitan inferir la capacidad de pago de los clientes y en particular lograr predecir el ingreso de un individuo.
¿La única manera de lograrlo es prediciendo el ingreso exacto de un cliente?
Para la ejemplificación del caso de estudio se utilizará información del mes de abril del año 2019.

Fig. 1 – Universo de clientes
La variable que se intenta predecir en este modelo es el ingreso neto de la persona. Por tal motivo se tratará de resolver con modelos de regresión. Sin embargo, hay que dejar constancia que se puede optar por utilizar un tipo de estrategia diferente. Por ejemplo, se puede tratar de predecir si el ingreso de la persona está por encima o debajo de un umbral predefinido. En este caso el problema cambia radicalmente y se debe tratar como un problema de clasificación.
Obteniendo variables que permitan realizar la mejor predicción
 El gran desafío es poder lograr encontrar aquellas variables que permitan realizar la predicción del ingreso de un individuo con la mayor exactitud. En esta primera etapa del proceso es fundamental el rol del analista, en particular oficiando de nexo entre el negocio que es quien tiene el mayor conocimiento y el equipo de desarrollo, para lograr así tener una buena sinergia que se traduzca en la obtención de las mejores variables para alimentar el modelo.
El gran desafío es poder lograr encontrar aquellas variables que permitan realizar la predicción del ingreso de un individuo con la mayor exactitud. En esta primera etapa del proceso es fundamental el rol del analista, en particular oficiando de nexo entre el negocio que es quien tiene el mayor conocimiento y el equipo de desarrollo, para lograr así tener una buena sinergia que se traduzca en la obtención de las mejores variables para alimentar el modelo.
Para este caso de uso particular, esta etapa culminó con el convencimiento de que los diferentes tipos de deuda de las personas en el Sistema Financiero serían las variables más importantes y que permitirían un buen acercamiento hacia el objetivo de poder predecir el ingreso de un individuo.
Un análisis de cosechas marca un punto de inicio ideal para ir preparando el terreno con una gran cantidad de variables generadas a partir de las deudas de las personas en el Sistema Financiero.
Este análisis implica contar con una base que contenga información relacionada a las deudas de las personas en diferentes productos a lo largo del tiempo.
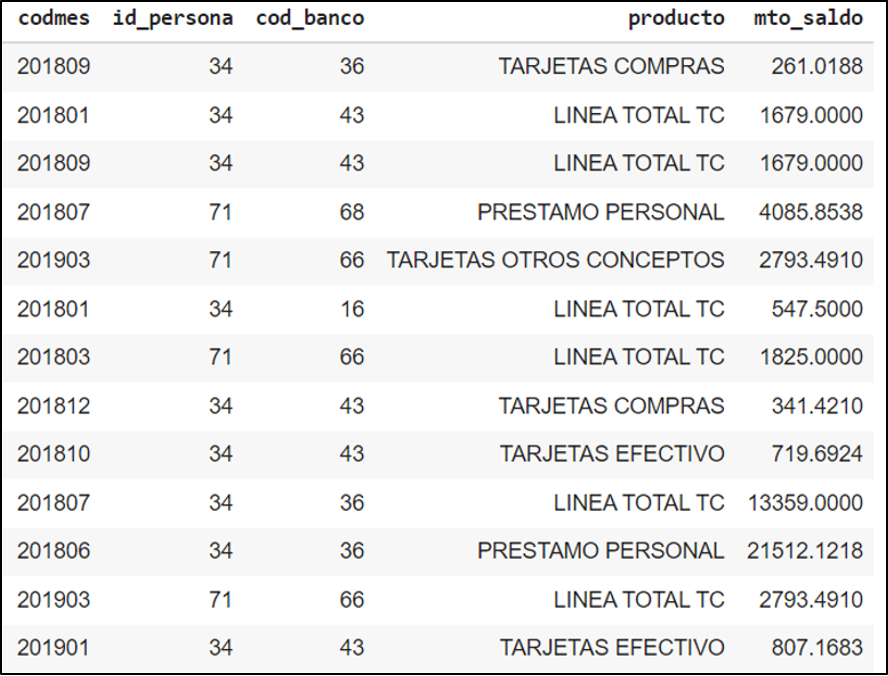
Fig. 2 – Ejemplo de dataset inicial para realizar análisis de cosecha
Análisis de cosecha
En este ejemplo se trabaja con información de clientes del mes abril de 2019. Con este punto de partida lo que se realiza en un análisis de cosechas es revisar la información histórica hacia atrás del universo de clientes que se va a analizar. Se comienza en marzo 2019, luego febrero 2019 y así sucesivamente.
Es buena idea comenzar el estudio realizando un análisis de 6 meses para atrás eligiendo variables claves por Institución Financiera tales como:
- Línea de crédito en Tarjetas de Crédito
- Saldo de la deuda en Tarjeta de Crédito
- Saldo de deudas relacionadas a Préstamos Personales
- Saldo de deudas relacionadas a Préstamos Hipotecarios
- Saldo de deudas relacionadas a Préstamos de Vehículos
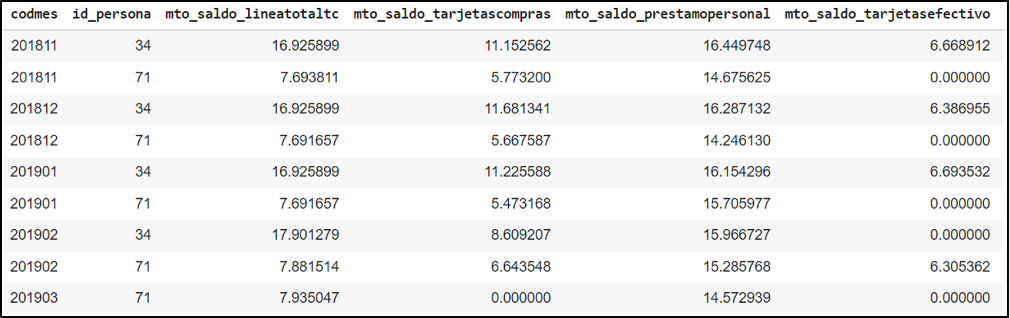
Fig. 3 – Primera transformación del dataset inicial
En el caso particular de las Tarjetas de Crédito se puede sumar una nueva variable que suele ser muy importante y es la diferencia entre la línea de crédito y la deuda.
Una vez obtenida la información histórica se pueden generar nuevas variables a través del análisis de diferentes mediciones estadísticas. A modo de ejemplo se puede comenzar analizando cada variable anterior desde las siguientes perspectivas:
- Promedio de los últimos 3 meses
- Promedio de los últimos 6 meses
- Incremento producido en los últimos 3 meses
- Incremento producido en los últimos 6 meses
- Frecuencia en los últimos 3 meses
- Frecuencia en los últimos 6 meses
- Desviación en los últimos 3 meses (variabilidad de la deuda)
- Desviación en los últimos 6 meses
Finalmente se podría completar el puzzle añadiendo variables relacionadas a la información demográfica, vehicular, etc.
¿Y qué tan fiable es esa predicción?
 En todo modelo de regresión y en particular en aquellos usados para estimar los ingresos se utilizan las métricas clásicas:
En todo modelo de regresión y en particular en aquellos usados para estimar los ingresos se utilizan las métricas clásicas:
- Error Cuadrático Medio
- R Score
- Promedio del Error Absoluto
- Promedio del porcentaje del Error Absoluto
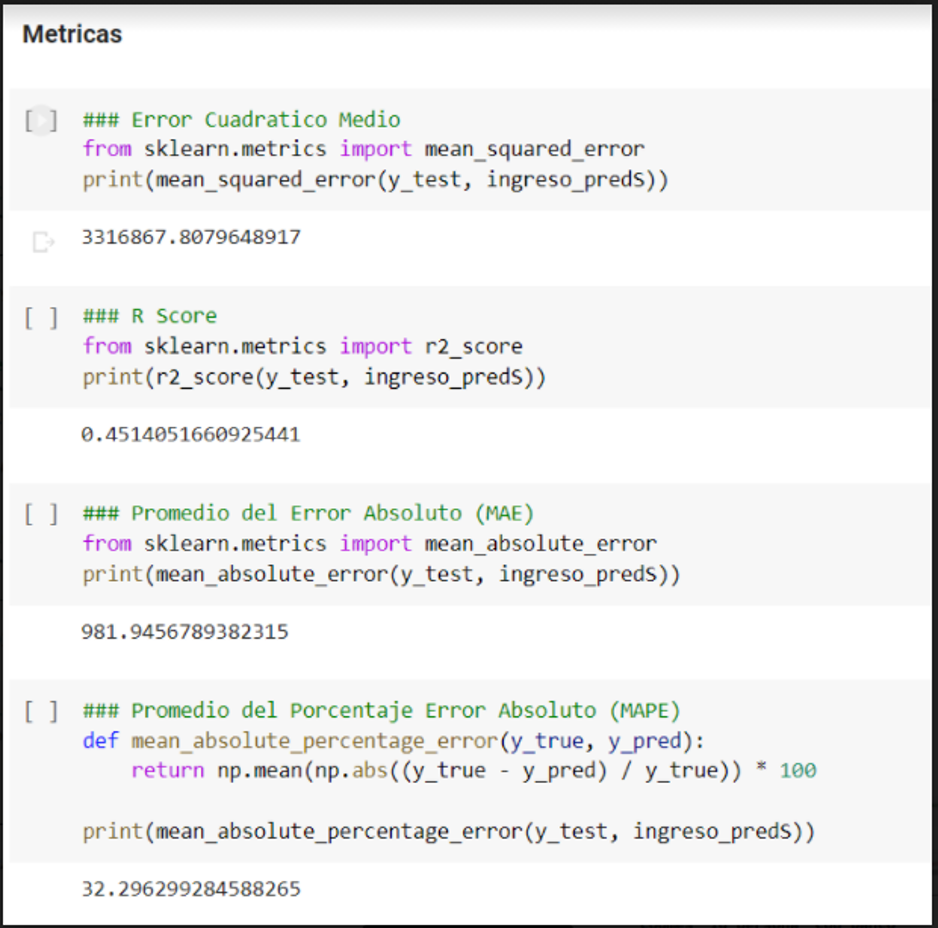
Fig. 4 – Métricas clásicas en modelos de regresión
Sin embargo, estas métricas por sí mismas no le reflejan al negocio con claridad el error real que se puede estar cometiendo en las distintas estimaciones. Para presentar la medición del error en este tipo de modelos el analista debería tomar la diferencia entre el ingreso verdadero y el ingreso predictivo para finalmente estimar el porcentaje del error por rango. Para ser más claros, al momento de definir el error que se está cometiendo debería presentarse al negocio una clasificación similar a la del siguiente ejemplo:

Fig. 5 – Medición del error en modelos de estimación de ingresos
En general se permite a lo sumo hasta un 20% del error, pero eso depende de cada Institución.
Con ese indicador se puede verificar que en un total de 4.831 casos, este baseline pronosticó por debajo de un error del 20% en 2.249 casos, lo que representa algo más del 46% del total.
Para seguir mejorando el modelo se puede apelar a aumentar el tamaño de la cosecha (hacerla de un año por ejemplo) y comenzar a iterar en la selección de las mejores variables y modelos hasta lograr obtener el óptimo que permita cumplir con los requisitos que el negocio estime necesario. Otra estrategia podría ser combinar modelos. Comenzar con un modelo de segmentación de clientes para luego aplicar diferentes modelos para cada uno de los segmentos identificados.
Conclusión
A diferencia de los proyectos clásicos de análisis, en donde el negocio tiene bastante claro cuáles son los pasos e incluso hasta dónde se puede llegar, en los proyectos de machine learning hay que estar iterando varias veces con el negocio, y en cada una de esas iteraciones hay que trasladar de la forma más clara y precisa posible los resultados que se van obteniendo y que tan cercanos se está de lograr la meta acordada.
El rol pedagógico del analista adquiere una gran importancia, porque en una realidad tan dinámica en una buena retroalimentación entre el negocio, al analista y el equipo de desarrollo estará la clave para el éxito en este tipo de proyectos.
Alexis Quintana
Consultor Data & Analytics – Quanam