

¿Dónde es más necesario crear liceos? Parte III
Si bien en la segunda parte del artículo comenté el cambio en el enfoque de la solución, no obtuve buenas soluciones. Evidentemente usando únicamente el factor de la distancia al liceo más cercano el algoritmo no predecía buenos lugares para construir los próximos, era necesario sumar más variables al análisis que fueran representativas del nivel educativo y socio-económico de la zona que se estaba analizando.
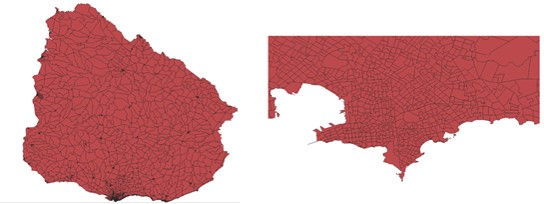
Para eso me bajé la información de personas de la Encuesta Continua de Hogares 2018, que para cada persona se indica el segmento censal en el que vive. El INE también provee un shapefile con los segmentos censales.
De las más de 400 variables que aparecen en la encuesta, había que seleccionar las que fueran representativas para este caso. Con ayuda de Germán Cotelo (Universidad ORT), Romina Superreguy (Universidad ORT) y Cecilia Cotelo (Banco Itaú), seleccionamos y a su vez ponderamos las variables a utilizar:

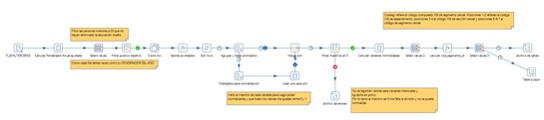
Para eso tuve que hacer un procesito en Pentaho Data Integrator (Kettle/Spoon), ya que tenía que primero sumarizar la información (hallar promedios) para tenerla a nivel de segmento censal y no de persona, filtrar para quedarme únicamente con personas menores a 30 que no hayan terminado el liceo aún, pivotear los valores de las variables, normalizar los valores para que para cada variable vayan siempre de 0 a 1, etc.
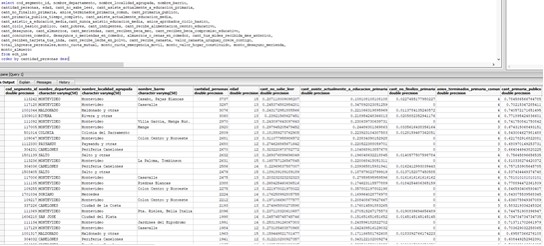
Al final del proceso queda la tabla cargada, para cada variable de las definidas tiene el valor real y el valor normalizado.
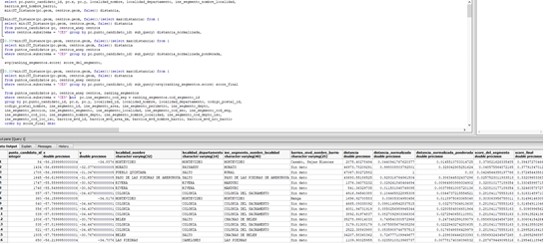
Para tener el score de cada segmento censal de acuerdo a lo que se había definido lo que hice fue crear una vista

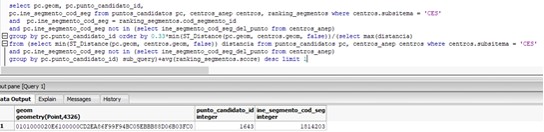
Con todo eso pronto, la Query para tener el peso de cada uno de los puntos candidatos es la siguiente:
El primer punto se inserta en la tabla de centros_anep con un flag que indique que es inventado y se vuelve a correr ya que hay que recalcular la distancia al liceo más cercano teniendo en cuenta al recién creado. En realidad, la versión real que utilicé fue esta que te da el geom y todo prontito para insertar:
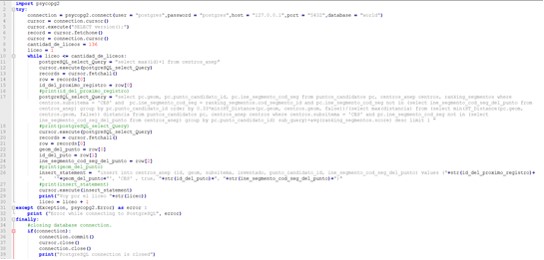
En el código Python:
Y el resultado es el siguiente:
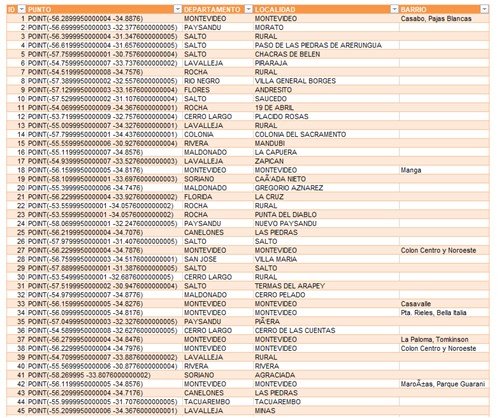
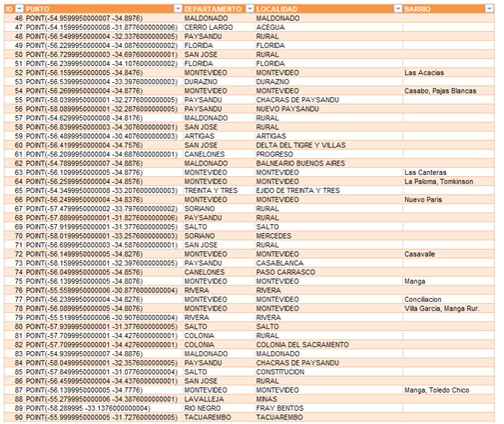
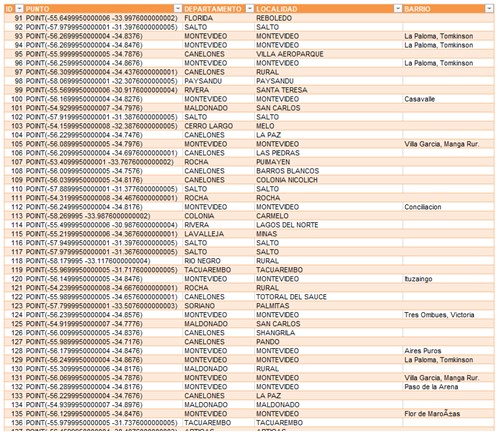
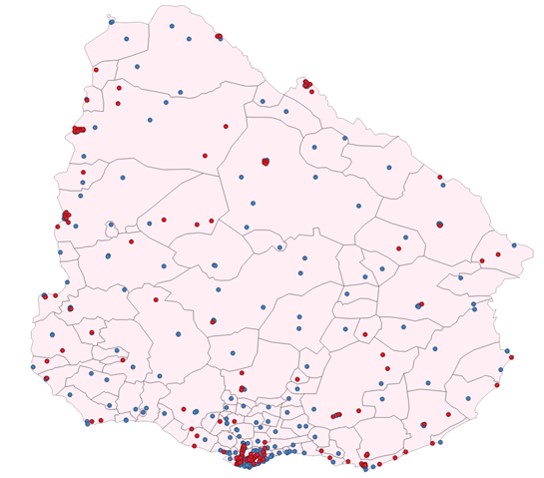
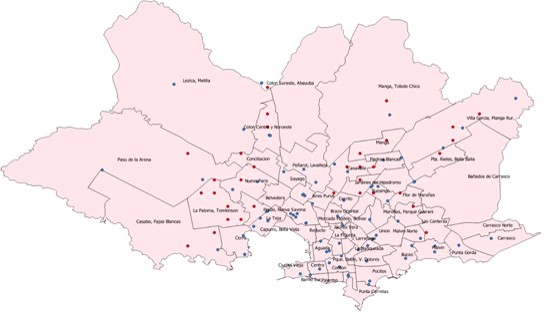
Conclusiones
Hay varias herramientas interesantes para hincarle el diente: geopandas, fiona, shapely, pyproj, geopyspark, and arcpy
El Spatial Data Science se viene y con fuerza. Hay muchas problemáticas de negocio que se pueden resolver mediante estas técnicas. Desde problemas muy similares al que se resolvió (donde conviene ubicar una policlínica, un ATM o una nueva sucursal de mi supermercado), hasta cuestiones más complicadas como por ejemplo:
- qué regiones son buenas para comprar terrenos para invertir.
- Verificar si existe algún patrón espacial que determine la prevalencia de alguna enfermedad y si existe, averiguar qué factores regionales son los que contribuyen a una mayor o menor prevalencia de enfermedades.
- Diseño óptimo para una red de vigilancia mediante cámaras, ya sea para defensa, control de tránsito, prevención de robos, etc.
- Optimización de rutas.
Consultor en Business Analytics & Information Management