

BIGDATA: saber buscar
It is a capital mistake to theorize before one has data. Insensibly, one begins to twist the facts to suit theories, instead of theories to suit facts. Sherlock Holmes
En un mundo hiperconectado, donde múltiples fuentes producen textos, señales y contenidos desde incontables dispositivos, convertir «datos» en «información» es una tarea que demanda innovación, pero además, conocimiento del área de aplicación, sea esta el tráfico de una ciudad, la banca, la industria manufacturera, o cualquier campo de las ciencias médicas.
Hoy día es habitual escuchar sobre deep learning, data mining, machine learning y otros términos afines, una tendencia de tópicos fácil de corroborar en Google Trends para los últimos cinco años, por ejemplo.
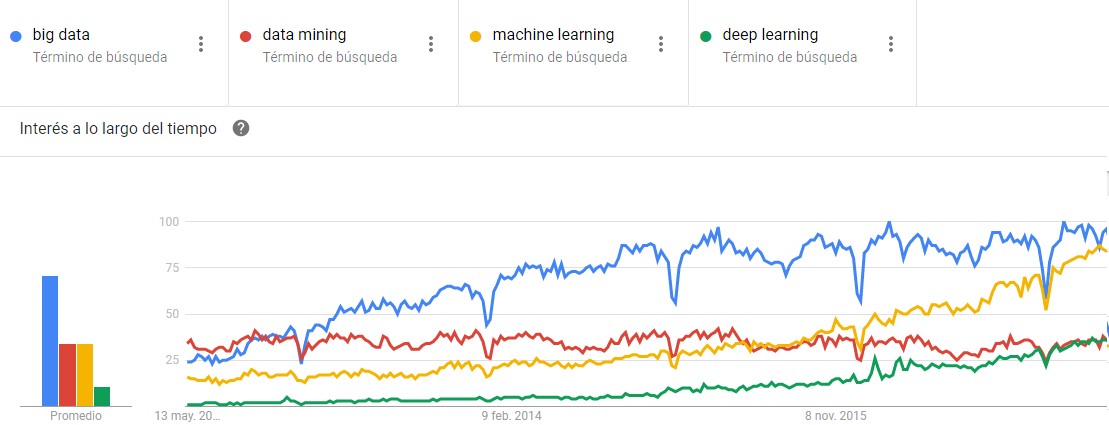
Sin embargo, estos conceptos han estado entre nosotros desde hace décadas: las primeras redes neuronales datan de los años sesenta, y también la madura minería de datos ha mutado -como intuimos en el gráfico- hacia otras denominaciones más recientes. En verdad, esta es la gran novedad: la tecnología detrás de bigdata es el gran habilitador, para que ejercicios otrora limitados al círculo exclusivo de las agencias de investigación o el ámbito académico estén al alcance de las empresas de todos los tamaños y complejidad organizacional. No en vano, aparatos y productos que usamos todos los días, están aprovechando este conocimiento en métodos y algoritmos desde hace varios años, desde detectar la sonrisa antes de disparar una foto, hasta predecir cuándo estamos en riesgo de perder un cliente.
Hemos leído repetidamente que «los datos son el nuevo petróleo», pero en verdad son mucho más que eso: no representan ningún peligro ecológico, y son accionables, nos ayudan a tomar decisiones. Pero sobre todo, son inagotables. Del data warehouse (1) al data lake (2) no hay una transición; hay una evolución complementaria. La discusión que se ha dado en ese tópico, no hace más que reforzar las virtudes de cada una de esas prácticas, ya una en la habilidad exploratoria, o la otra en el manejo de volúmenes infinitamente escalables y fuentes diversas.
Así, hemos visto una explosión de ofertas de productos y servicios en la última década –Hadoop (3) acaba de cumplir diez años-, donde es fácil encontrarse en el medio de un laberinto de opciones para «hacerlo todo». Y es que una maqueta puede hacerse con un mecano, o con un kit de bloques, pero puede no ser buena idea mezclar ambos. Ahí aparecen las decisiones de diseño y arquitectura, donde queremos acompañar a nuestros clientes.
Fernando López Bello @fer_lopezbello
Ingeniero en Computación, PMP
Especialista en Big Data
1 Repositorio de información, componente medular de business intelligence, donde se concentran e integran diversas fuentes para realización de analíticas del negocio. 2 Extensión para escalar el concepto de Data Warehouse a big data: mucha información (terabytes, petabytes), de fuentes muy diversas, generados a gran velocidad. 3 Marco de operación para procesamiento y almacenamiento de información a gran escala, constituido por un conjunto de productos de código abierto, de los cuales el pilar principal es el sistema de archivos distribuido HDFS (Hadoop Distributed File System).