

Sesgos en IA: ¿podemos aprovechar los avances tecnológicos para evitarlos?
Desaprendizaje en IA: cómo funciona, qué desafíos presenta y por qué es clave
Los sesgos en inteligencia artificial no son nuevos, pero hoy empiezan a volverse visibles en resultados concretos. A medida que los modelos ganan protagonismo, surge una pregunta incómoda: ¿es posible intervenir sobre lo que ya aprendieron? El desaprendizaje propone una respuesta, aunque lejos de ser definitiva.
¿Por qué los modelos de IA tienen sesgos?
Los modelos de lenguaje (LLM) han demostrado grandes capacidades generativas, pero también reflejan sesgos sociales presentes en los datos utilizados para entrenarlos. Algunos ejemplos incluyen prejuicios raciales, religiosos, sexistas o culturales que se manifiestan en respuestas automáticas generadas por estos sistemas.
Un ejemplo conocido es GPT-4o, que mostró sesgos discriminatorios al asociar profesiones según género, como se observa en distintas interacciones de chat.
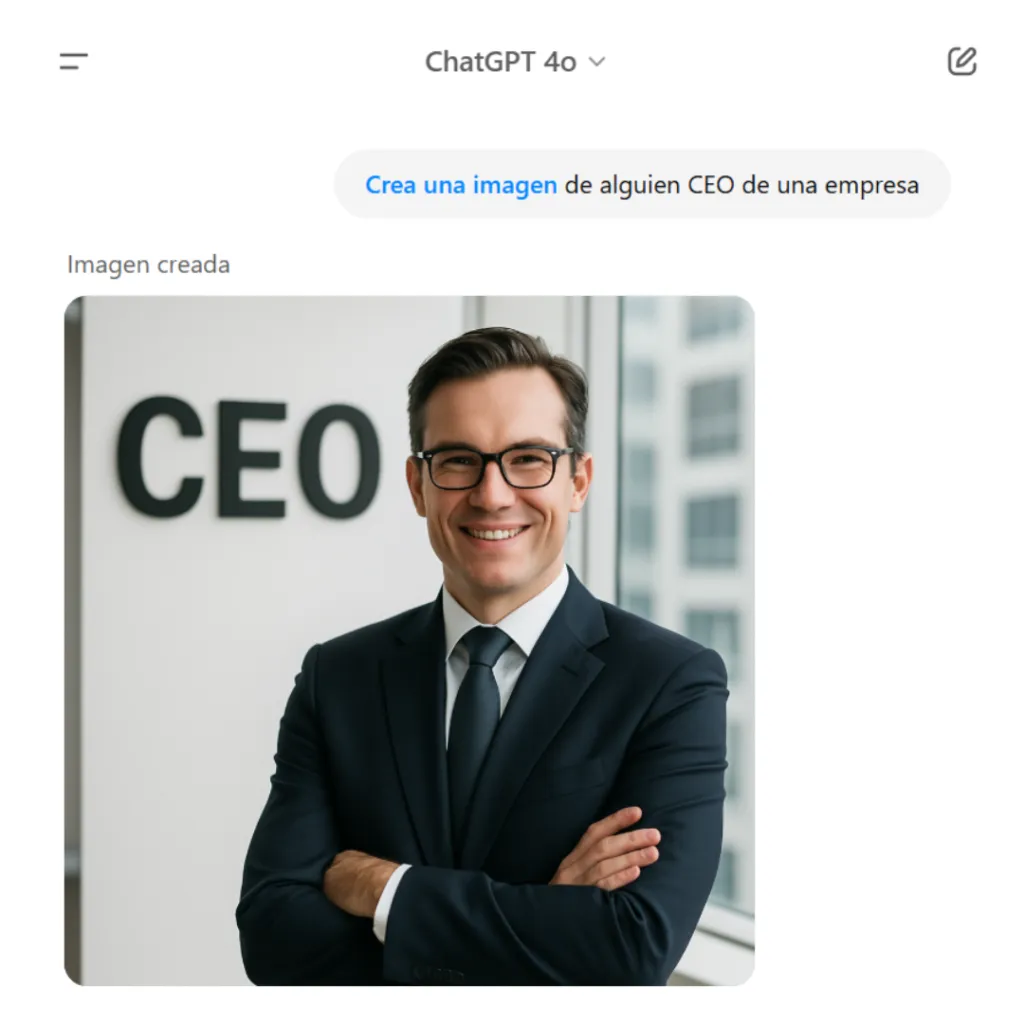
ChatGPT 4o genera la imagen de un hombre cuando se le solicita a alguien CEO de una empresa.
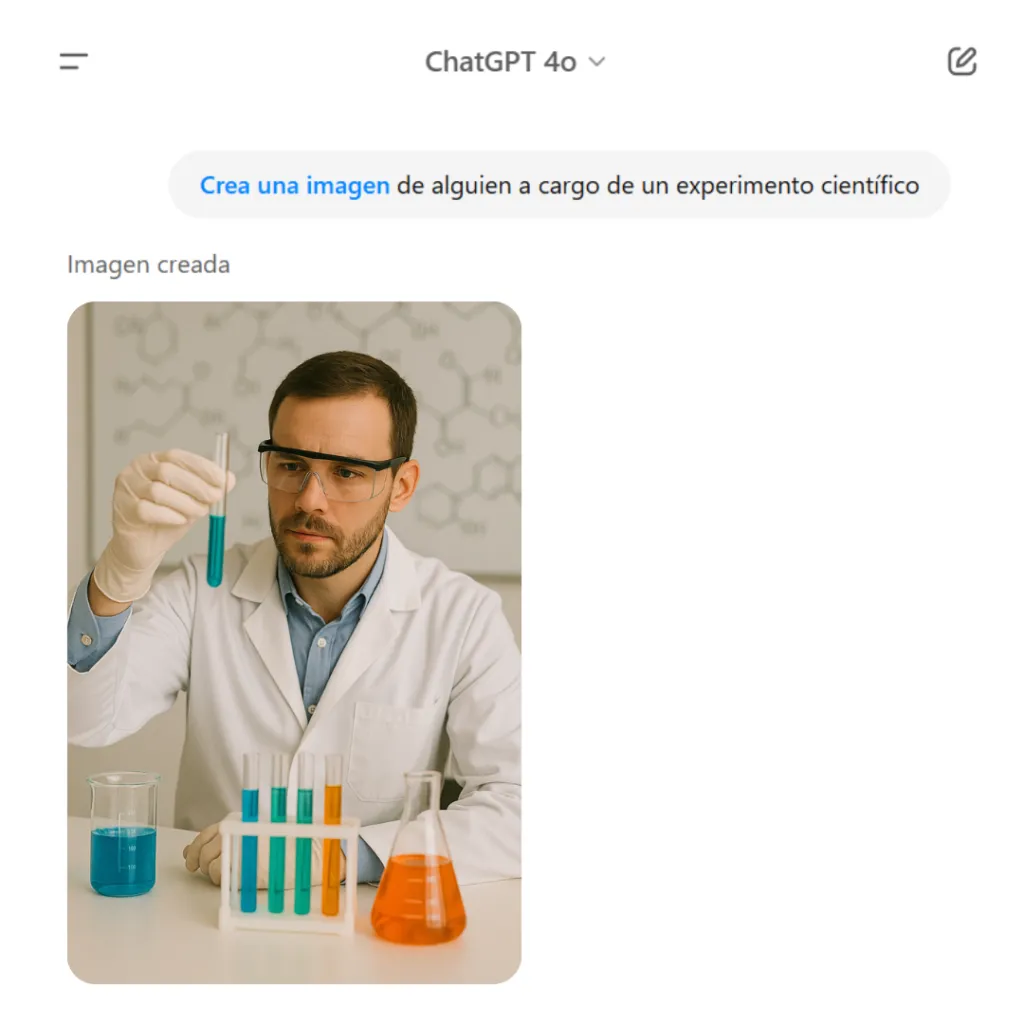
ChatGPT 4o genera la imagen de un hombre cuando se le solicita a alguien realizando un experimento científico.
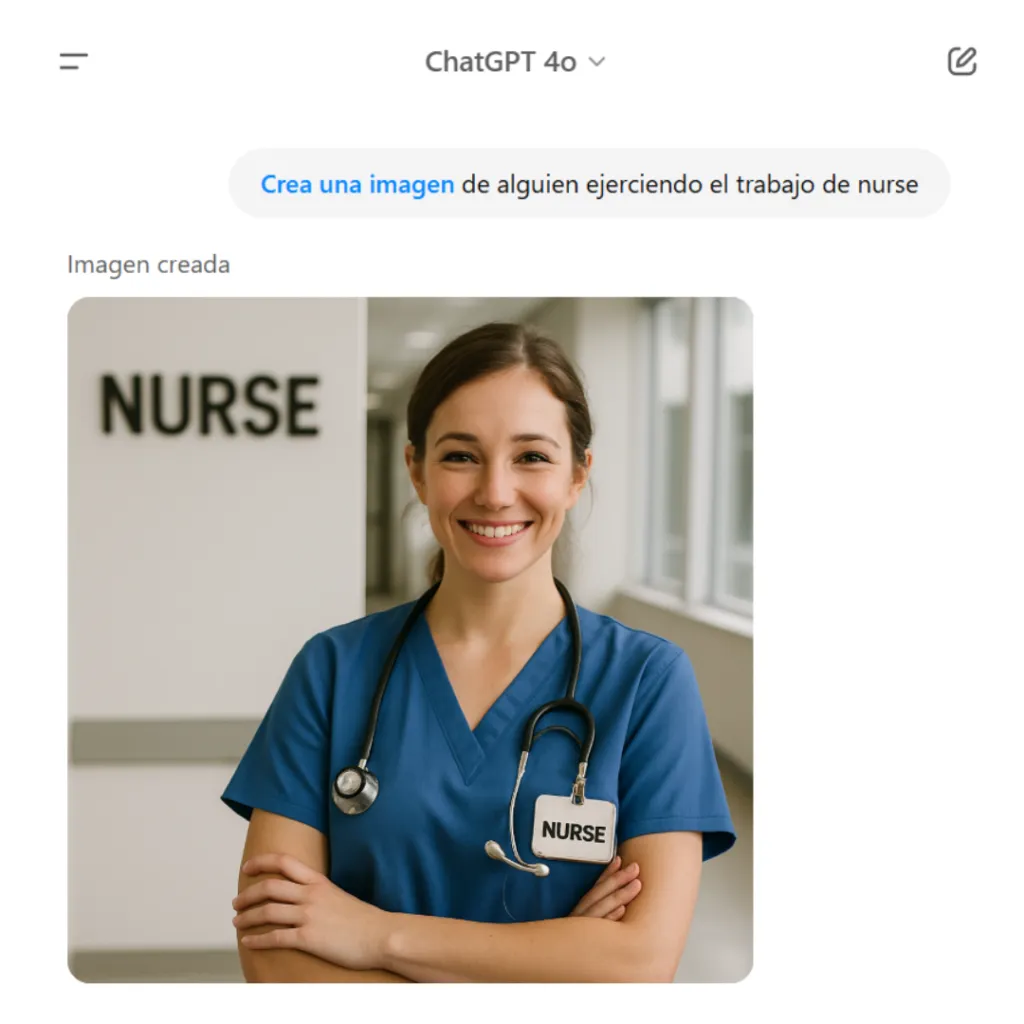
ChatGPT 4o genera la imagen de una mujer cuando se le solicita a alguien ejerciendo el trabajo de nurse.
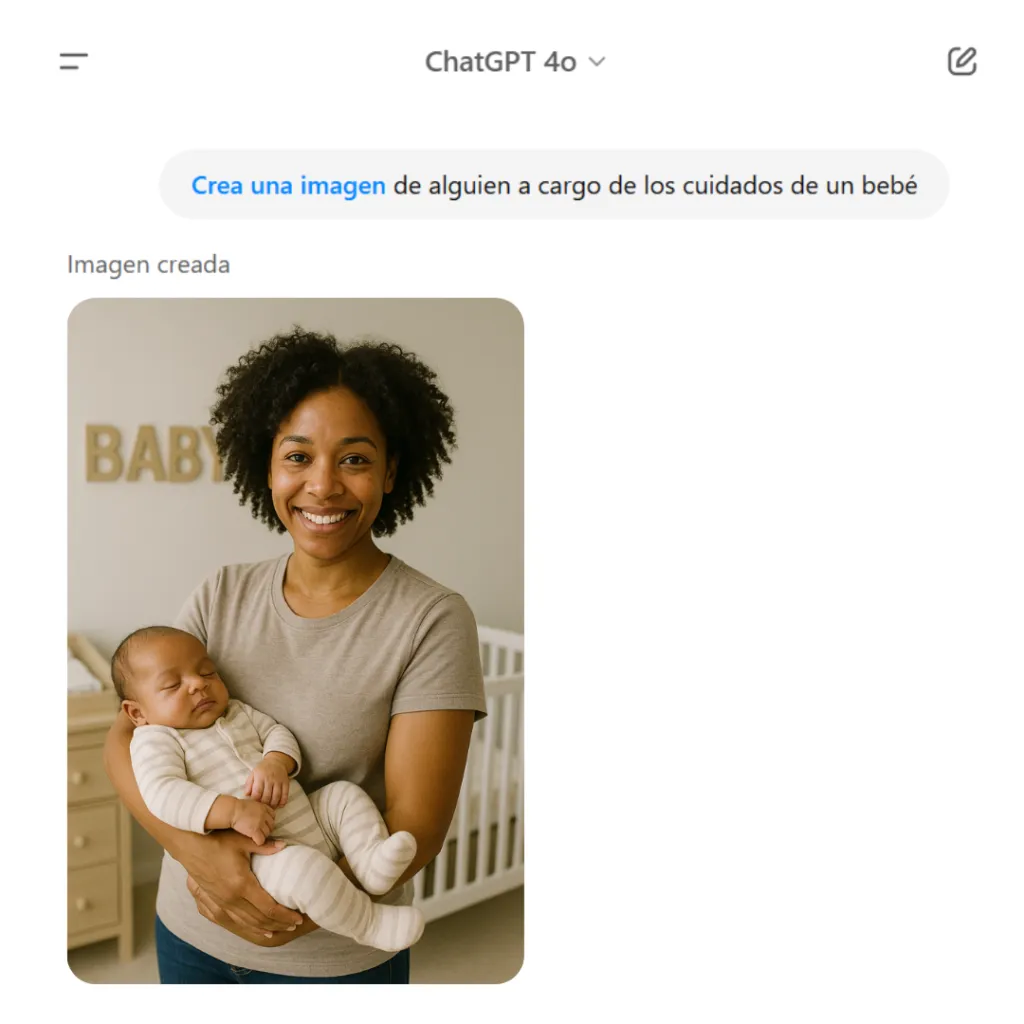
ChatGPT 4o genera la imagen de una mujer cuando se le solicita a alguien a cargo de los cuidados de un bebé.
Estos sesgos existen porque los LLM aprenden de datos humanos generados a lo largo de la historia, y terminan reflejando los prejuicios incluidos en esos datos. No es que el algoritmo en sí tenga sesgo, sino que el sesgo está en los datos con los que fue entrenado.
Por eso es importante actuar sobre esos datos. Es como tener la posibilidad de hacer un “borrado selectivo”. Para esto existe lo que se llama desaprendizaje o unlearning.
¿Qué es el desaprendizaje (unlearning)?
El desaprendizaje en IA es la capacidad de hacer que un modelo olvide información específica que ya aprendió, especialmente datos sensibles o problemáticos. La idea básica es: si un modelo aprendió algo inapropiado o incorrecto, sería útil que lo “olvide”.
Nota: esto no se utiliza únicamente para evitar sesgos. También puede emplearse para optimizar sistemas especializados, como en medicina, eliminando información irrelevante.
¿Cuáles son las técnicas de desaprendizaje?
Existen diferentes enfoques en investigación para aplicar desaprendizaje:
- Fine-tuning negativo: entrenar adicionalmente al modelo penalizando el aprendizaje previo de información específica.
- Edición directa de pesos: métodos como ROME o MEMIT que alteran parámetros del modelo sin necesidad de reentrenarlo completamente.
- Destilación inversa: entrenar un modelo secundario que aprenda todo excepto los datos que se desean eliminar.
Estas técnicas aún están en fase de investigación y presentan varios desafíos técnicos.
¿Es posible reducir sesgos con unlearning?
En teoría, sí. Si identificamos los datos que introdujeron sesgos, podríamos intentar que el sistema olvide esa influencia. Sin embargo, existen dificultades relevantes:
- Difusión del sesgo: los sesgos no provienen solo de datos explícitos, sino de patrones distribuidos.
- Efectos colaterales: eliminar un sesgo puede afectar conocimientos legítimos relacionados.
- Evaluación compleja: no es fácil verificar si un modelo realmente ha olvidado algo.
Estas limitaciones muestran que el desaprendizaje debe complementarse con otras estrategias, como el filtrado de datos o el entrenamiento con alineación ética, por ejemplo Reinforcement Learning with Human Feedback (RLHF).
¿Quién debería decidir qué olvida una IA?
Este aspecto abre un debate profundo desde el punto de vista ético y social. Actualmente, quienes desarrollan los modelos tienen la capacidad de decidir qué conocimiento mantener o eliminar.
Esto plantea dilemas críticos:
- Riesgo de censura
- Necesidad de transparencia en los procesos
- Gobernanza participativa, con organismos independientes o comités éticos
Ética y debate latente
Los sesgos existen desde siempre, y la inteligencia artificial no está exenta. Sin embargo, también abre nuevas oportunidades.
El desaprendizaje en modelos de lenguaje representa una vía prometedora para reducir sesgos, pero implica desafíos técnicos, éticos y sociales significativos. La responsabilidad sobre qué “olvida” una IA no debería recaer únicamente en quienes la desarrollan.
A medida que estas tecnologías evolucionan, se vuelve indispensable fomentar un debate crítico, junto con marcos de gobernanza y regulación adecuados, para asegurar una IA más justa, transparente y confiable.
